Evaluating model reliability under a distribution shift that we do not have samples from is challenging. Our new work introduces dataset interfaces: a scalable framework that synthesizes counterfactual examples for a given dataset under user-specified shifts.
Suppose that we want to deploy an ImageNet-trained classifier to identify objects in image scenes (such as dogs, plates, chairs, etc). Ideally, we would like this model to perform reliably in a variety of contexts, including under distribution shift: for example, changes in background, object pose, or data pipeline that are underrepresented in the training dataset. How can we ensure that our model will perform well in such cases?
As a concrete example, consider checking that our model reliably identifies plates captured in unexpected locations (such as “in the desert” or “in the grass”). A natural way to do that is to acquire counterfactual examples: images that conform to the training distribution except for a specified change. In our example scenario, such counterfactual examples correspond to images of plates that are located in the grass but otherwise match the ImageNet distribution in terms of style, lighting, camera angle, etc.
How can we procure such images? One common approach is to query an image search engine, such as Google or Bing:
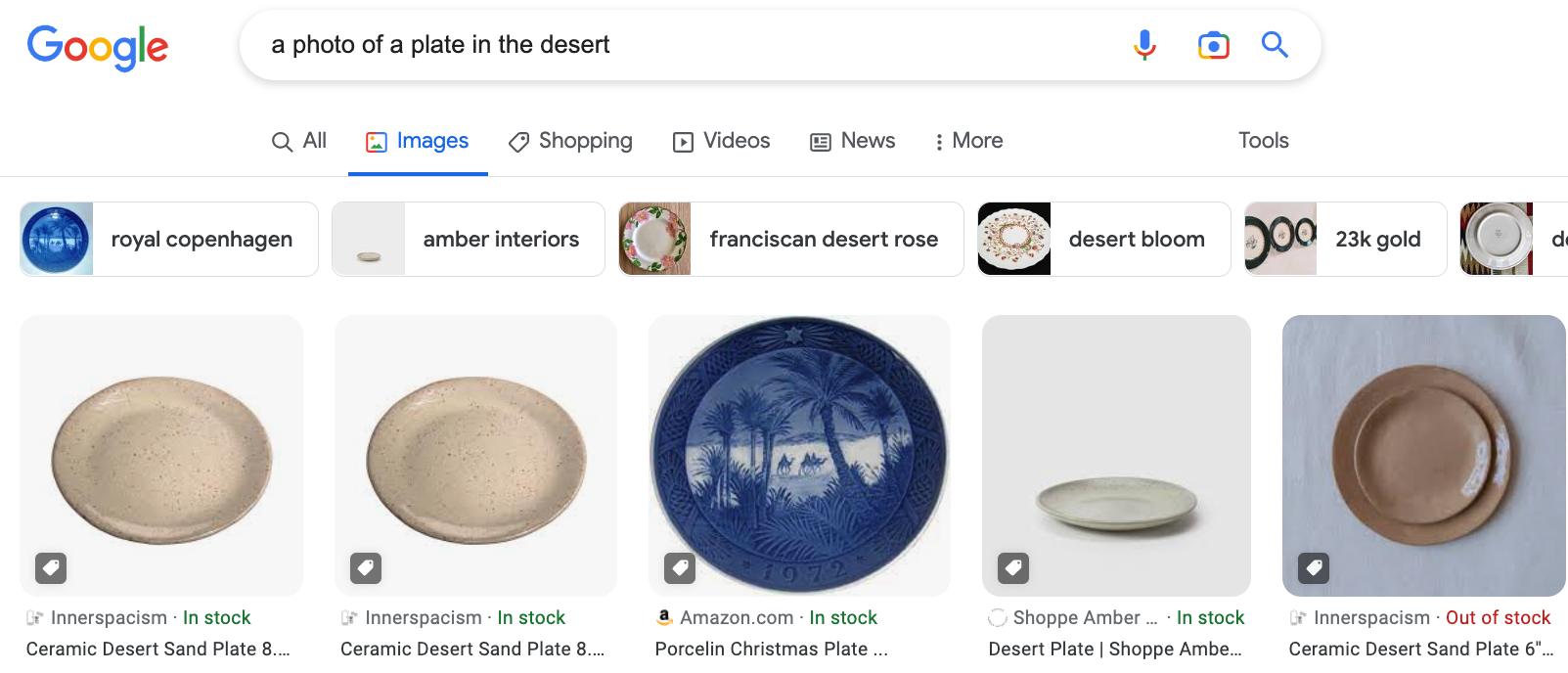
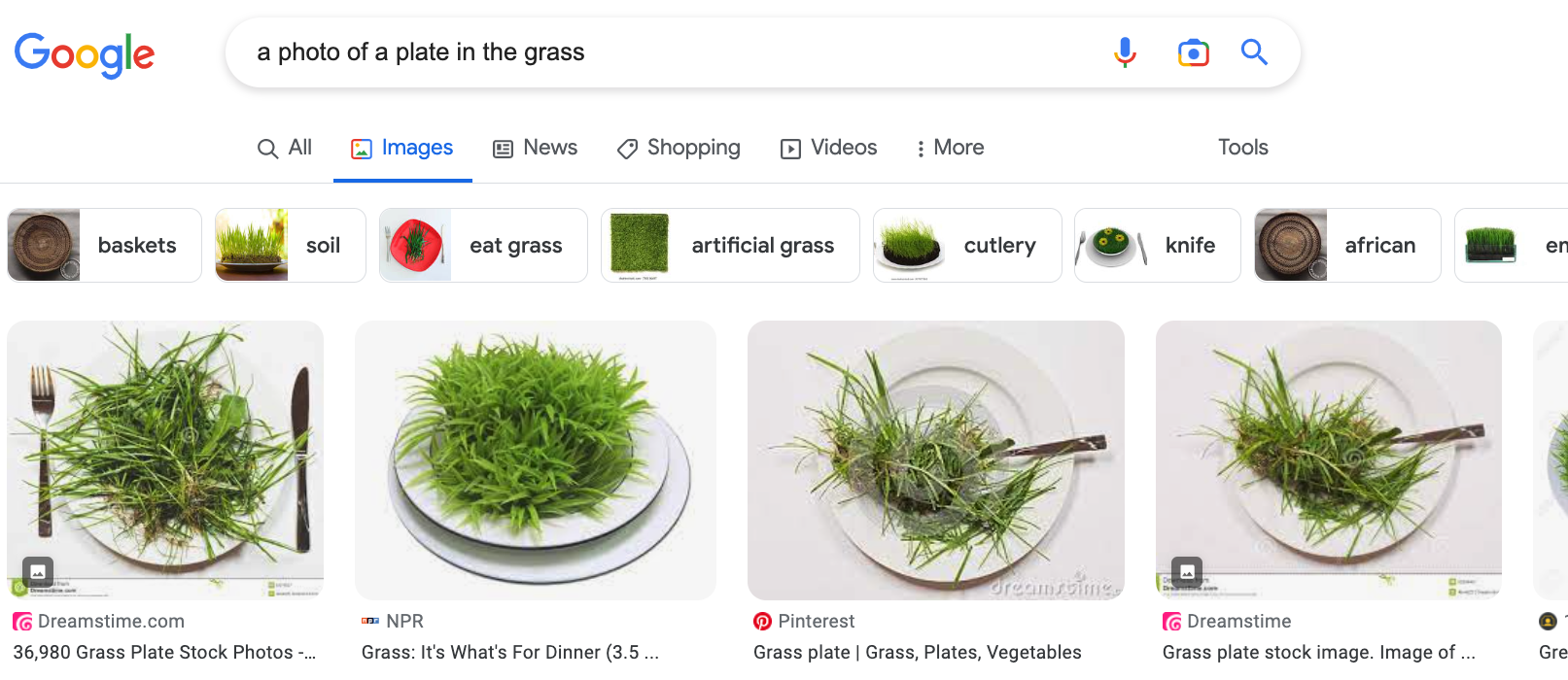
Unfortunately, while the search engine does yield images of plates, they don’t quite capture the desired distribution shift. Image search gives us images of “plates in the desert” on white backgrounds, not the desert! And rather than plates on grass, we get grass on plates!
It appears such specific queries are simply too challenging for search engines. So, let’s take a different approach. What if, instead, we use a text-to-image generative model, such as Stable Diffusion, DALL-E 2, or Imagen? These models, which generate photorealistic images conditioned on text, can generate never-before-seen scenes , like avocado-shaped chairs. Would such generative models fare much better? Let’s query one of them—Stable Diffusion—with the name of the class (e.g., “A photo of a plate in the grass.”). Here is what we get:

Nice! The synthesized photos convincingly portray plates on grassy backgrounds, as desired.
However, something unexpected happens: when we evaluate our ImageNet-trained classifier on these images, it achieves a paltry accuracy of only 2%! Is the grassy background really such a catastrophic failure for our model?
Turns out: prompting Stable Diffusion with the class name “plate” introduces a confounding shift. Specifically, while ImageNet plates usually contain food, the plates generated by Stable Diffusion are almost entirely empty. Thus, our ImageNet-trained classifier fails even when generating plates with no (specified) shift—we get 5% accuracy even when we evaluate our model on images generated with the prompt “a photo of a plate”!

Can we then find a way to capture such rare shifts (e.g. “plate in the grass”) while still properly generating objects matching those found in the original distribution (e.g. the kinds of plates found in ImageNet)?
Dataset Interfaces
This is where dataset interfaces, our new framework that scalably synthesizes counterfactual examples for a given dataset under user-specified shifts, comes in.
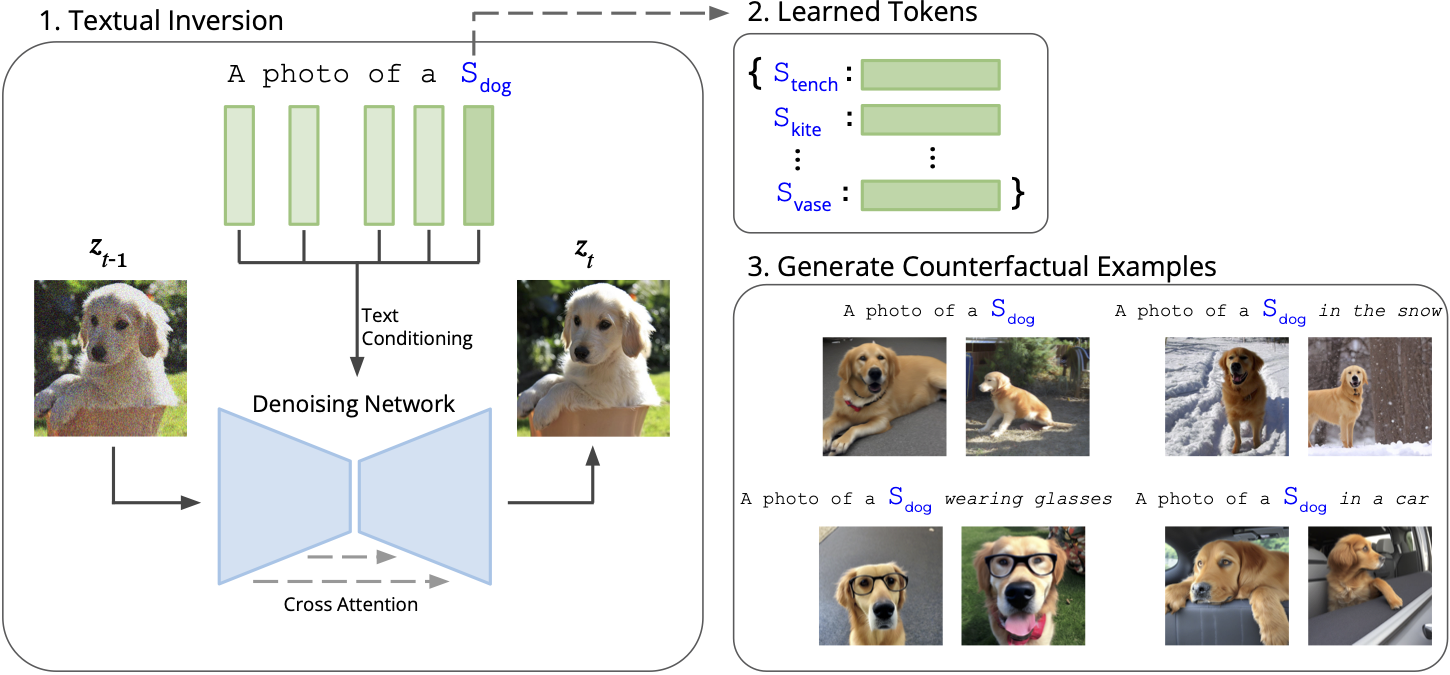
Our framework still uses text-to-image generative models (we use Stable Diffusion) to synthesize such counterfactual examples. However, as seen above, we need a much more precise way to capture underlying concepts (classes) than just prompting such a model with the class name. To this end, we leverage textual inversion, a technique that aids in generating objects that are difficult to express with standard, human-language prompts. In textual inversion, we use a set of images containing a desired visual concept to learn a new “word” (token) S* meant to represent the concept whenever used in a prompt. Then, we can use this token in place of the class name in prompts to generate images more closely aligned to the objects as captured in the original dataset of interest (in our case, ImageNet).
Now, to construct our dataset interface, we run textual inversion on images of each class in the input dataset separately, learning a corresponding class token Sc for each. Then, by incorporating these tokens into our prompts, we can generate images that more closely match the corresponding class (as represented in the input dataset) under specified shifts. For example, to generate an image of a dog on the beach, we can use the prompt: “A photo of a Sdog on the beach.” Below is an overview of our approach.
ImageNet*
To demonstrate our framework in action, we create ImageNet*, a dataset interface for the ImageNet dataset. As we see below, ImageNet*-generated images match those of ImageNet much more closely than images generated by just prompting Stable Diffusion with the class name.

Now that we are able to match the original distribution, we can create proper counterfactual examples. Specifically, we use ImageNet* to generate a benchmark for distribution shift robustness of counterfactual examples for 23 shifts, including changes in background, weather, lighting, style, attributes, and co-occurrence. Here are some of the resulting images:
You can find the corresponding benchmark here. We also release the original ImageNet* tokens here—we are excited to see what kind of shifts people can capture with them!
Model Debugging
Now, with a dataset interface (such as ImageNet*) in hand, how can we diagnose model failures? Let’s return to our example of evaluating an ImageNet-trained classifier’s performance on “plates in the grass.” Recall that when we prompted Stable Diffusion with the class name, we introduced a confounding shift of emptiness, and the classifier’s accuracy dropped to 2%.
Let’s apply now dataset interfaces to try and disentangle these two shifts. To this end, we use ImageNet* to generate counterfactual examples of “plates in the grass” and “empty plates” separately. We find that our classifier’s accuracy only slightly drops on plates in the grass, from 90% to 75%. However, on empty plates, our classifier’s performance severely degrades to 6%!

So, indeed, it was the emptiness—not the grassy background—that was the cause of the catastrophic performance drop that we observed. Since dataset interfaces generate images that closely match the input distribution, we can test these distribution shifts in isolation without worrying about such hidden confounding shifts.
A shift-centric perspective on robustness
Beyond helping us surface individual model failures, dataset interfaces enable a new, broader perspective on model robustness.
Many previous works have studied how different types of models are able to handle distribution shifts. However, these works are only able to study one, or a handful of distribution shifts at a time. By harnessing the capabilities of dataset interfaces, we can compare the behavior of a wide range of (23) shifts all at once, yielding a new view on robustness.
To understand how a given distribution shift impacts different models, we can first collect a set of ImageNet models and evaluate them on images that reflect that shift. We then can plot each model’s in-distribution accuracy against its performance on images under this shift (see below for two examples): each point represents one model.
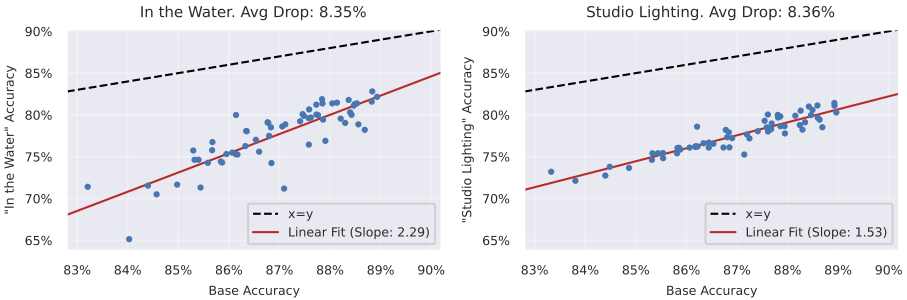
Looking at the plot above, we see that these two shifts, “in the water” and studio lighting”, exhibit different behavior! While both lead to the same average drop in performance, “in-distribution” accuracy improvements generally correspond to larger accuracy increases on “in the water” images than “in studio lighting” images. We can quantify this difference by looking at the slope of the line fit to the model accuracies on the plot (the higher the slope, the more benefit we gain from improved models).
Motivated by this difference, we can categorize the behavior of each shift in our benchmark based on two criteria:
- Absolute impact: the shift’s overall severity, measured as the average drop in accuracy due to the distribution shift.
- ID/OOD slope: the degree to which in-distribution accuracy translates to improvement on the images under the distribution shift, measured as the slope of the plot described above
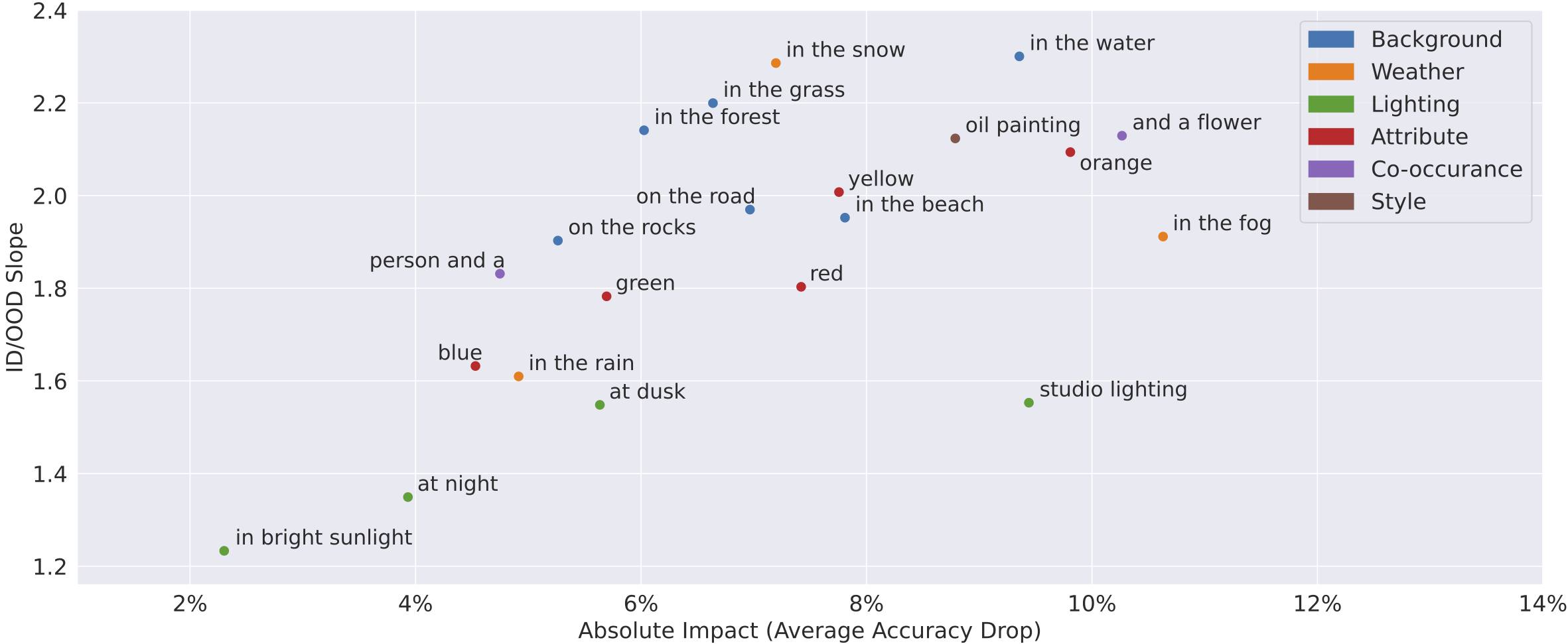
As our first plot suggested, different types of shifts manifest different behaviors. For example, even though “in the forest” and “at dusk” have similar absolute impacts, “in the water” has a higher ID/OOD slope. Thus, while improving in-distribution performance translates to better accuracy on “in the forest” images, the model’s behavior on “at dusk” images is much more static. In general, we find that shifts based on lighting have lower ID/OOD slope than those based on background. The above is just an example of how our framework enables one to study not only how a given distribution shift impacts different models but also how different distribution shifts vary in terms of their impact on such models.
Conclusion
In this post, we introduce dataset interfaces: a framework which allows users to scalably synthesize counterfactual examples with fine-grained controls. Our framework generates images that match key aspects of the input dataset’s distribution, enabling us to test distribution shifts in isolation. Also, thanks to its scalability, dataset interfaces allow users to evaluate a wide array of shifts.