In our last post, we introduced a task–component modeling–for understanding how individual components contribute to a model’s output. The goal there was to predict how a given model prediction would respond to “component ablations”—targeted modifications to specific parameters. We focused on a special “linear” case called component attribution, where we (linearly) decompose a model prediction into contributions from every model component, as shown below:
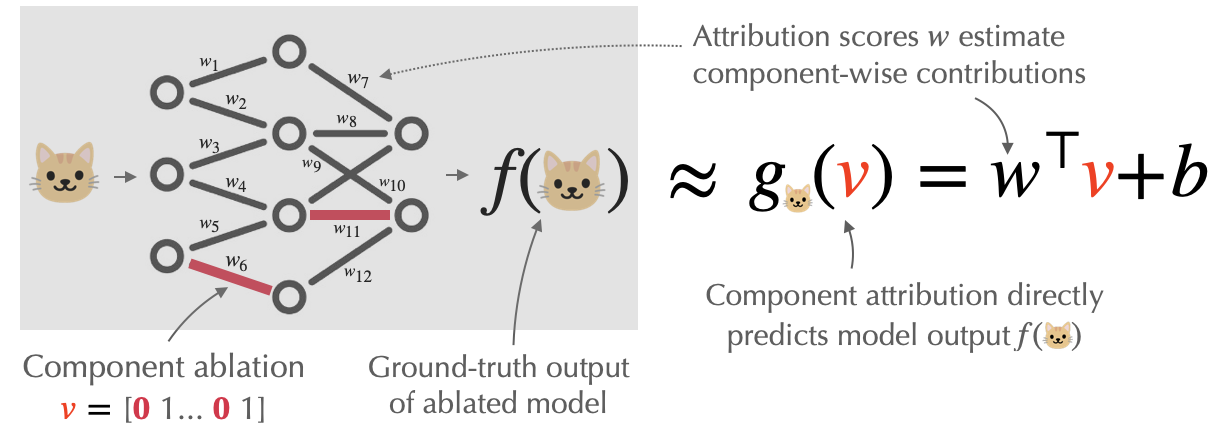
We then presented a method, called COAR (Component Attribution via Regression), which estimates component attributions that accurately estimate the effect of component ablations at scale. We ended our last post by asking what the practical utility of these component attributions is.
In this post, we’ll show that component attributions enable fine-grained edits to model behavior! The key here is a fundamental connection between the attribution problem and the editing problem. On one hand, the component attribution task focuses on the question: “How would the model’s output change if we were to ablate a subset of components?” On the other hand, model editing inverts this question and asks: “Which components, when ablated, would change the model’s output in a specific way?” This suggests that we can directly use component attributions to identify a subset of model components that, when ablated, induce a targeted change in model predictions, as illustrated below:
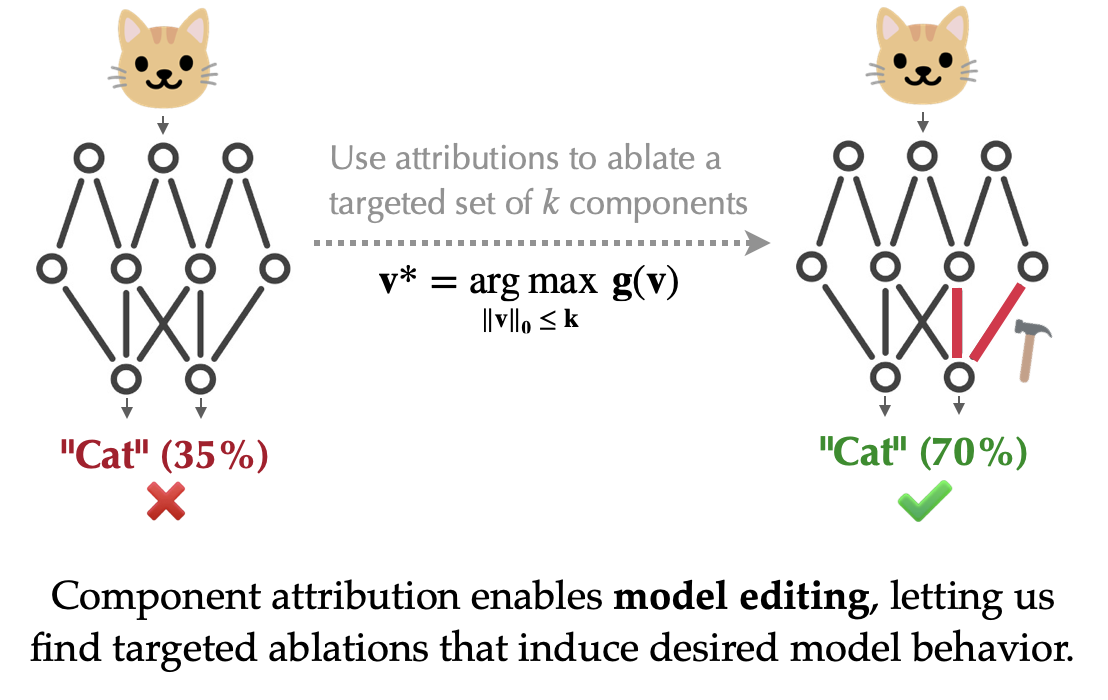
Editing models with component attributions
Building on this connection, we propose a simple yet effective editing approach called COAR-Edit. Given a set of target examples (where we want to modify a model’s behavior) and a set of reference examples (where we want behavior to be unchanged), COAR-Edit identifies a subset of components to ablate using COAR attributions alone:
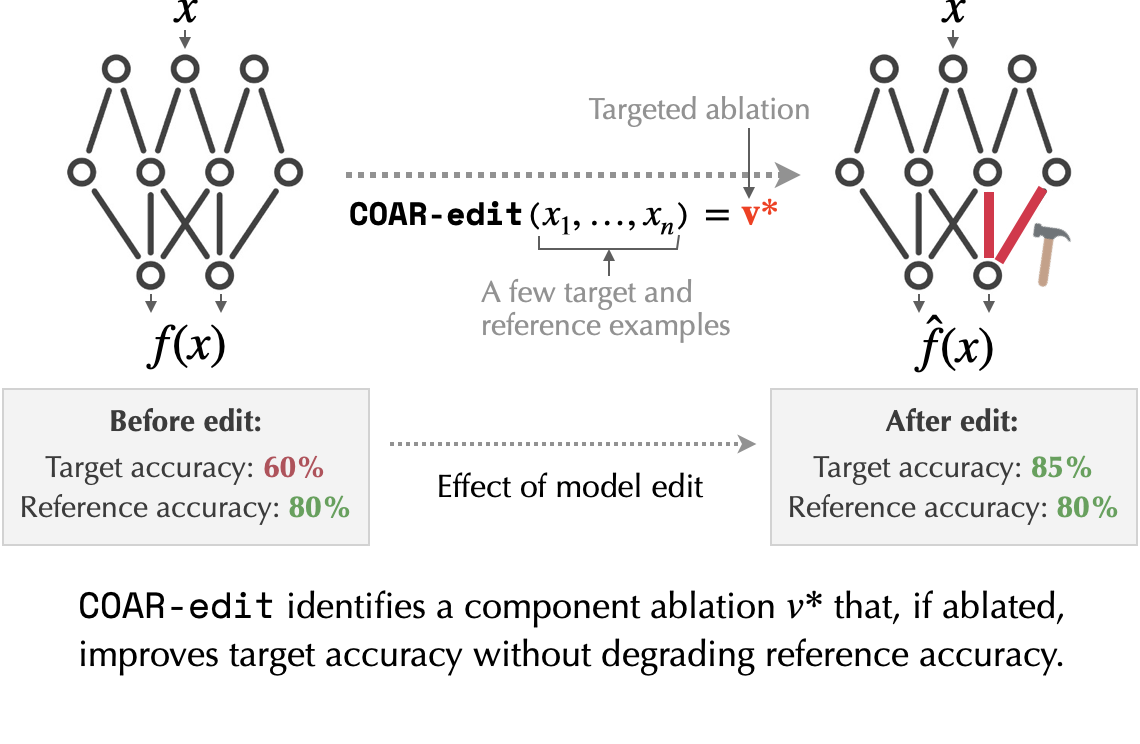
More concretely, to identify this subset of components to ablate, COAR-edit uses the following three-step procedure:
- Step 1: Estimate COAR attributions for each target and reference example. Recall that each of these attributions provides a “score” to each model component indicating the effect of that model component on the corresponding example’s prediction.
- Step 2: For every model component, estimate its importance to target examples relative to reference examples. To quantify importance, we use a simple t-test, with a null hypothesis being that the attribution scores of the given component are distributionally similar over target and reference examples.
- Step 3: Ablate the bottom-k components with the lowest scores to improve model performance on the target examples. Conversely, ablate the top-k components to worsen model performance on the target examples.
Intuitively, the three steps above find a subset of components that most significantly impact the target examples compared to the reference examples. Furthermore, our approach does not require any additional training–it simply ablates a small subset of components to induce a change in model behavior!
Given the simplicity of our approach, it is natural to ask, is COAR-edit actually effective at editing larger-scale neural networks? To answer this question, in our paper we stress-test our editing approach on five tasks: fixing model errors, ``forgetting’’ specific classes, boosting subpopulation robustness, localizing backdoor attacks, and improving robustness to typographic attacks—we describe two of these below.
Case study: Boosting subpopulation robustness
We know that models tend to latch onto spurious correlations in training data, resulting in subpar performance on subpopulations where these correlations do not hold. Can we edit trained models post hoc to improve performance on under-performing subpopulations?
Setup
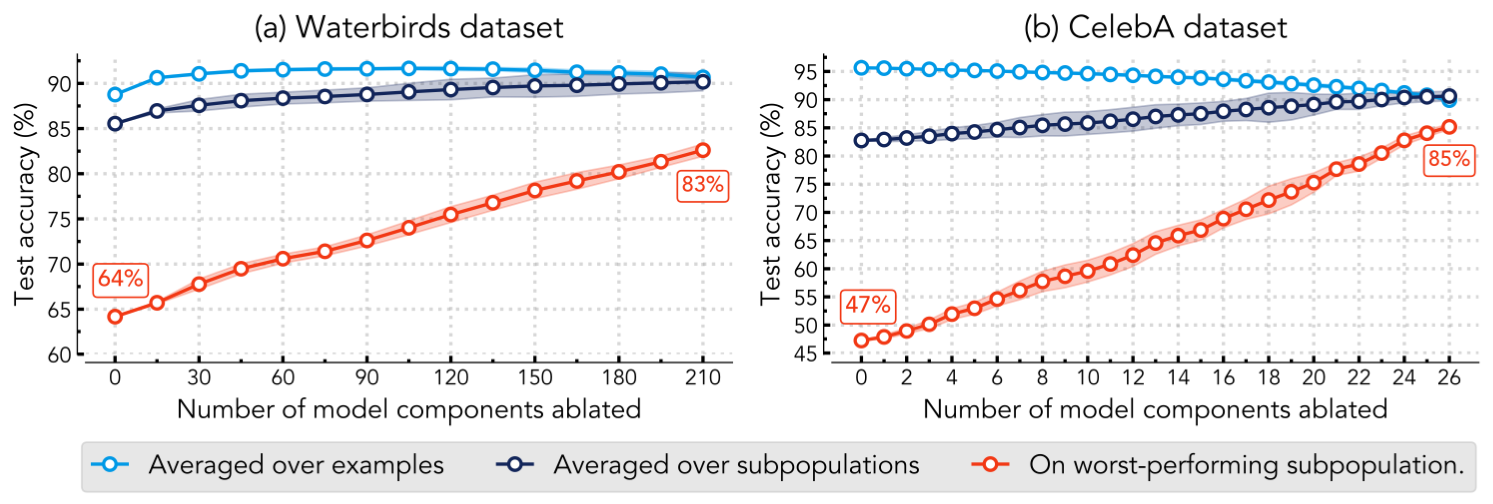
We consider two benchmark datasets for subpopulation robustness: Waterbirds and CelebA. On both datasets, we fine-tune an ImageNet pre-trained ResNet50 model, where each model component is one of 22,720 convolution filters in the model. As expected, the fine-tuned models fare poorly on “minority” groups that are underrepresented in the training data, (e.g., “blonde males” in CelebA, or “land birds on water backgrounds” in Waterbirds). Taking a few examples from these minority groups as “target” examples and a few examples from majority groups as “reference” examples, we apply COAR-edit to identify components that, when ablated, improve performance on the former without changing performance on the latter.
Results
As shown below, COAR-edit boosts worst-subpopulation performance (red) on both datasets without impacting accuracy averaged over examples (dark blue) or subpopulations (dark blue). On the left, editing by ablating 210 of 22, 720 components in the ResNet50 improves worst-subpopulation accuracy on Waterbirds from 64% to 83%. Similarly, editing the CelebA model by ablating just 26 components improves the worst-subpopulation accuracy from 47% to 85%. Furthermore, our approach is sample-efficient, as COAR-edit does not require subpopulation-level annotations for the entire training dataset—just 20 (random) training examples from each subpopulation suffice. Also, unlike specialized methods such as GroupDRO, our approach does not need to train a new model from scratch!
Case study: mitigating typographic attacks on CLIP
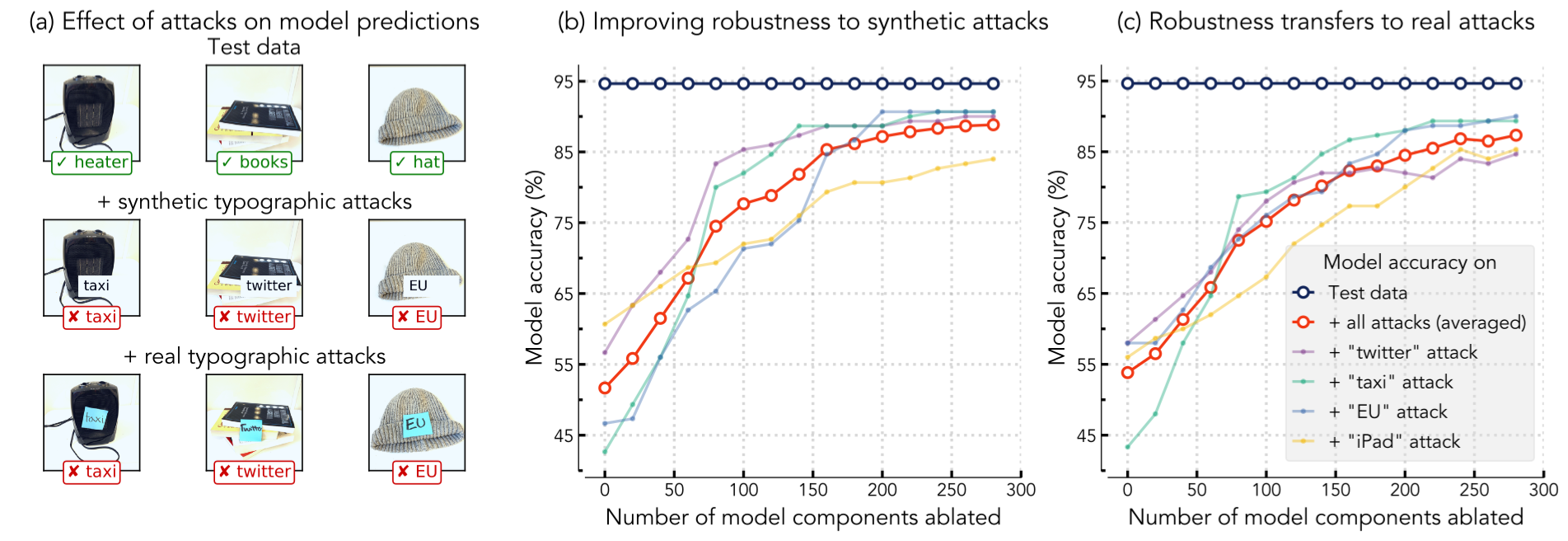
Zero-shot CLIP classifiers are vulnerable to typographic attacks that simply overlay text snippets (synthetic or real) to images in order to induce misclassifications—check out the figure below for an example. Can we edit CLIP classifiers to make them more robust to typographic attacks?
Setup
We use a dataset of household objects with and without typographic attacks to evaluate the robustness of a CLIP ViT-B/16. In a similar fashion to our last experiment, we apply COAR-edit to identify components that, when ablated, improve performance on “target” examples that contain synthetic typographic attacks (shown below) while maintaining performance on “reference” examples without attacks.
Results
The figure below summarizes our results. On the left, we show that the predictions of the unedited model can be manipulated to “taxi”, “twitter”, or “EU” via synthetic (middle row) or real (bottom row) typographic attacks. In the center panel, we find that ablating COAR-identified components in the ViT improves its average performance (red) on unseen examples with synthetic attacks from 51% to 89% without changing performance on examples without attacks. On the right, we show that our model edit transfers to unseen examples with real typographic attacks, improving accuracy from 54% to 86%.
Summary
To summarize, we’ve discussed how component attributions, estimated via COAR, can directly enable effective model editing without additional training. That is, by simply identifying and ablating “important” components, we can correct errors, improve robustness, and mitigate biases in a sample-efficient manner. Looking ahead, we are excited about using COAR to analyze structure in training data, probe neural network representations, and edit generative models!
Don’t forget to check out our paper or code repo for details, and feel free to leave any questions or comments below!