Read the paper Download the datasets
We discuss our recent paper on identifying the role of backgrounds in image classification. Along with our results, we’re releasing our code and datasets as a benchmark.
As we discussed in our last post, quantitative benchmarks are key drivers of progress across many computer vision tasks. On tasks like image classification, state of the art is often determined by models’ accuracies on standard datasets, such as CIFAR-10 and ImageNet. Still, model accuracy isn’t all that matters, as evidenced by investigations into robustness (e.g., [1]), reliability (e.g., [2]), and out-of-distribution performance (e.g., [3]). These properties are governed not only by models’ predictions on test data, but also by the specific set of correlations models use, and by how these correlations are combined to make predictions. For example, previous work has shown that model predictions can behave unexpectedly due to reliance on correlations that we humans don’t rely on (e.g. [4], [5], [6], [7]); or due to overusing even human-recognizable correlations such as texture (e.g., [8], [9]) or color (e.g., [10]). So it follows that if we want to understand these more complex properties of machine learning models, we must first be able to characterize the correlations that these models leverage.
Needless to say, a full characterization of the features and signals exploited by deep neural networks is far beyond the scope of any single paper. In our latest paper, we thus take a deep dive into one specific kind of signal: image backgrounds.
Backgrounds are an established source of correlation between images and their labels in object detection: ML models may use backgrounds in classification (cf. [11], [12], [13], [14]), and even human vision can make use of image context (cf. [15] and references). We thus want to understand better how current state-of-the-art image classifiers rely on image backgrounds. Specifically, we investigate the extent of this reliance, its implications, and how models’ use of backgrounds has evolved over time.
A new dataset (or seven)
Our main tool for understanding how models use background signals is a set of synthetic datasets that we refer to as ImageNet-9 (IN9). These datasets aim to disentangle images’ foreground and background signals and thus enable us to study their relative effects.
To generate ImageNet-9, we start by organizing a subset of ImageNet into nine
coarse-grained classes based on common ancestry in the WordNet hierarchy: the
resulting “super-classes” are dog, bird, vehicle, reptile, carnivore, insect,
instrument, primate, and fish. We call the 9-class dataset of unmodified images
Original.
We then use a combination of the bounding boxes
provided by ImageNet and the computer vision library OpenCV to separate the
foreground and background in
Once we’ve separated the foreground and background signals, we introduce seven new datasets, falling into three categories:
- Background-only datasets
- Only-BG-B: Black out the bounding boxes given by ImageNet annotations, leaving only the background.
- Only-BG-T: Take Only-BG-B and replace the blacked-out region with a tiled version of the rest of the image (the background).
- No-FG: Use OpenCV to extract the exact shape of the foreground, and replace it with black.
- Foreground-only datasets
- Only-FG: The exact complement of No-FG—rather than removing the foreground, remove everything else.
- Mixed datasets
- Mixed-Rand: For each image, overlay the foreground (extracted using OpenCV) onto the background from a different random image (again, extracted using OpenCV).
- Mixed-Next: Assign each class a number from 1 to 9. For each image of class $y$, add the background from a random image of class $y+1$ (or $1$, if $y=9$).
- Mixed-Same: For each image, add the background from a random image of the same class.
Putting ImageNet-9 to work
It turns out that these proposed ImageNet-9 datasets allow us to ask (and answer) a variety of questions about the role of background signals in image classification.
1. Is background signal enough for classification?
Before we look at the behaviour of standard ML models, we first double-check that background signals are exploitable in the first place—i.e., that models can learn reasonably accurate classifiers for natural images while being trained on backgrounds alone. We are not the first ones to consider this question (e.g., [13]) but it serves as a useful sanity check and gives us a baseline to compare the rest of our experiments to.
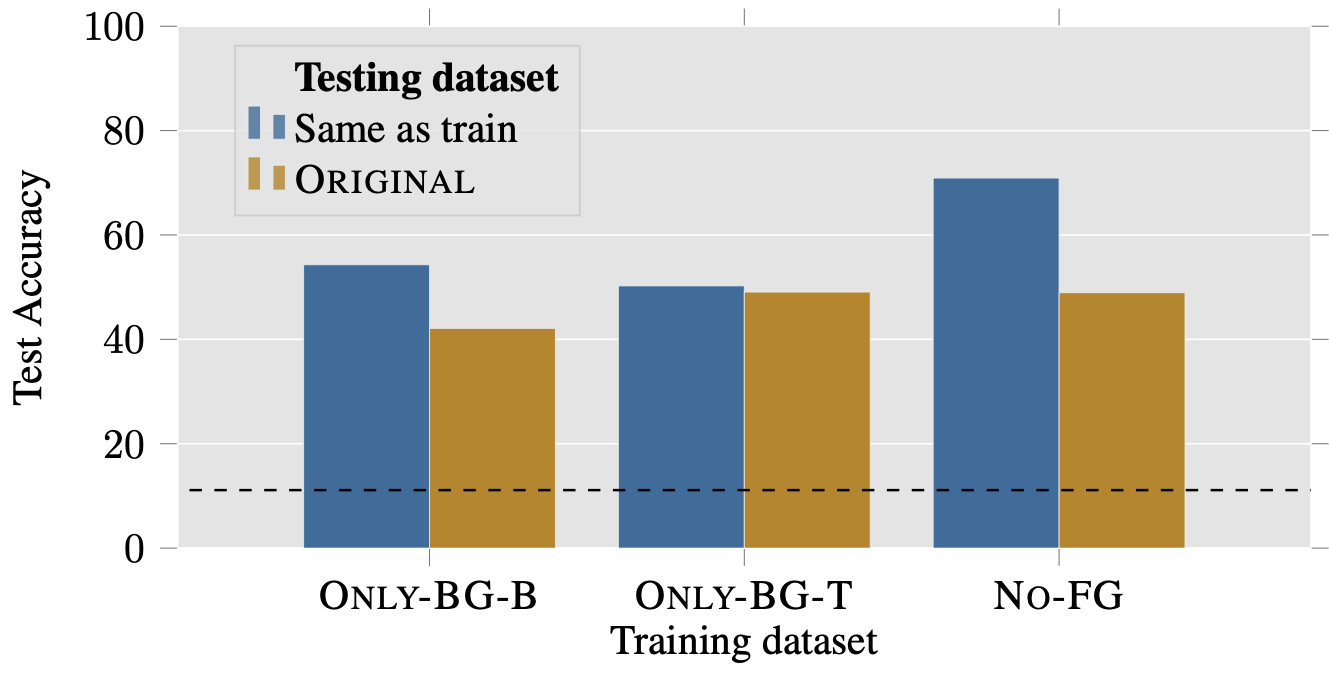
We train models on the Only-BG-T, Only-BG-B, and No-FG datasets; the models
generalize reasonably well to both their corresponding test sets and the Original
test set (each model gets around 40-50% accuracy: a random classifier would get
11%). Thus,
2. Do models actually use background signals?
So, backgrounds are indeed a useable signal for deep learning classifiers. That’s not necessarily bad, or even different to humans: if you see an occluded picture with an underwater background, you’d (hopefully) say that the pictured object is more likely to be a fish than a dog. On the other hand, humans are still able to call a dog a dog when it’s underwater, i.e., a misleading/irrelevant background usually does not preclude us from making the correct predictions. Is the same true for models?
To answer this question, we study model accuracies on the Mixed-Rand dataset,
where image backgrounds are randomized and thus provide no information
about the correct label.
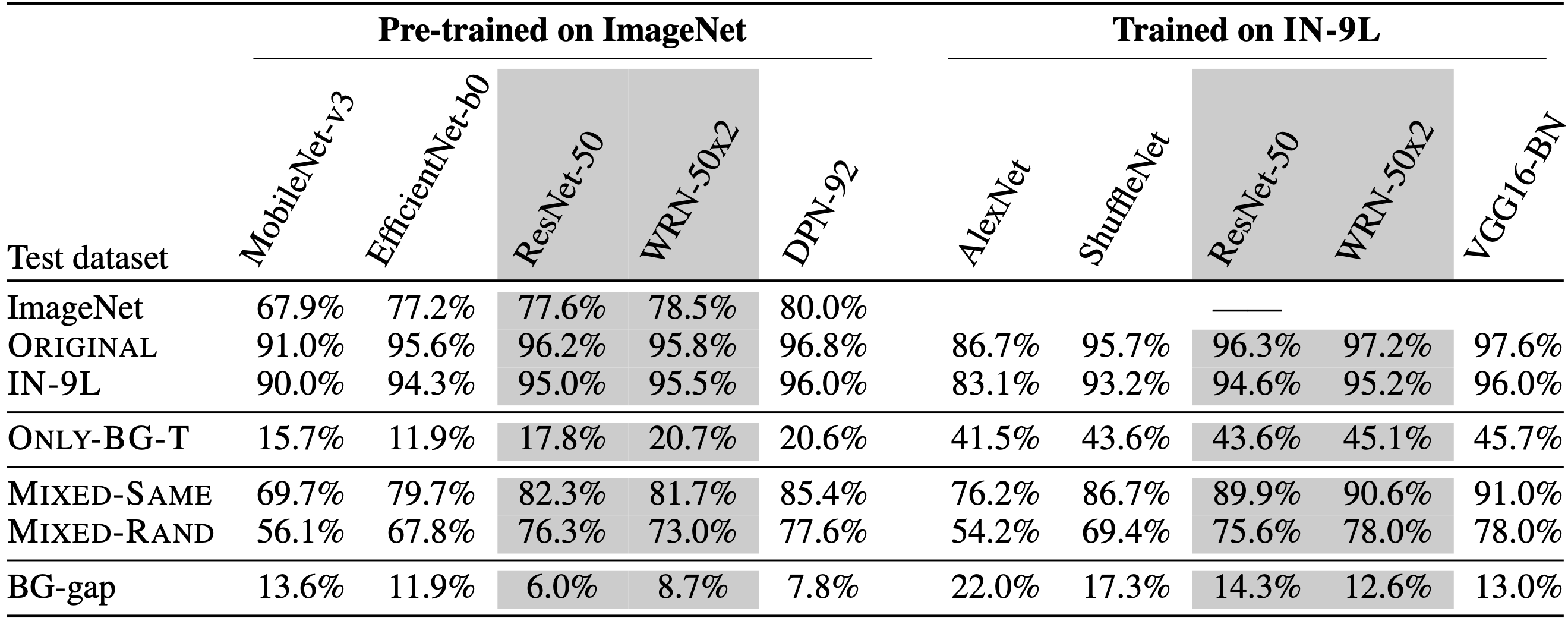
Specifically, we compare model performance on Mixed-Rand and Mixed-Same: the
latter maintains the foreground-background correlation (since the background is
from the correct class), while controlling for
We denote the accuracy gap between Mixed-Same and Mixed-Rand as the BG-Gap, i.e., the drop in model accuracy due to changing the class signal from the background. The table below summarizes our observations: the BG-Gap is 13-22% and 6-14% for models trained on IN-9 and ImageNet, respectively, suggesting that backgrounds often mislead state-of-the-art models even when the correct foreground is present. (As we discuss in Appendix B of our paper, ImageNet-trained models do seem to be more robust in this sense, but the reason for this robustness is hard to pin down.)
3. Ok, but how bad can it get?
The BG-Gap introduced in the previous experiment measures, in some sense, models’ average robustness to misleading backgrounds. What does the worst case look like? To diagnose just how large of an issue background over-reliance can be, we search for the worst extracted background corresponding for each extracted foreground. It turns out that a ResNet-50 model can be fooled on 87.5% of foregrounds by overlaying them on a corresponding “adversarial background.”
In fact, there also turn out to exist backgrounds that consistently affect the
prediction of the classifier regardless of what foreground is overlaid onto
them. The backgrounds below (extracted from insect images) fool our model into
predicting “insect” on up to 52\% of non-insect foregrounds:

Further, we can make the classifier predict “insect” on over 2/3 of the foregrounds in the ImageNet-9 dataset, just by combining the foregrounds with different insect backgrounds.
4. What is the effect of the training dataset?
So far, all of the models that we’ve looked at have been trained on natural data, i.e., either on the Original dataset from IN9, or on ImageNet itself. We now want to test whether the previously-observed dependence on backgrounds can be reduced (or removed altogether) by appropriately altering the training data.
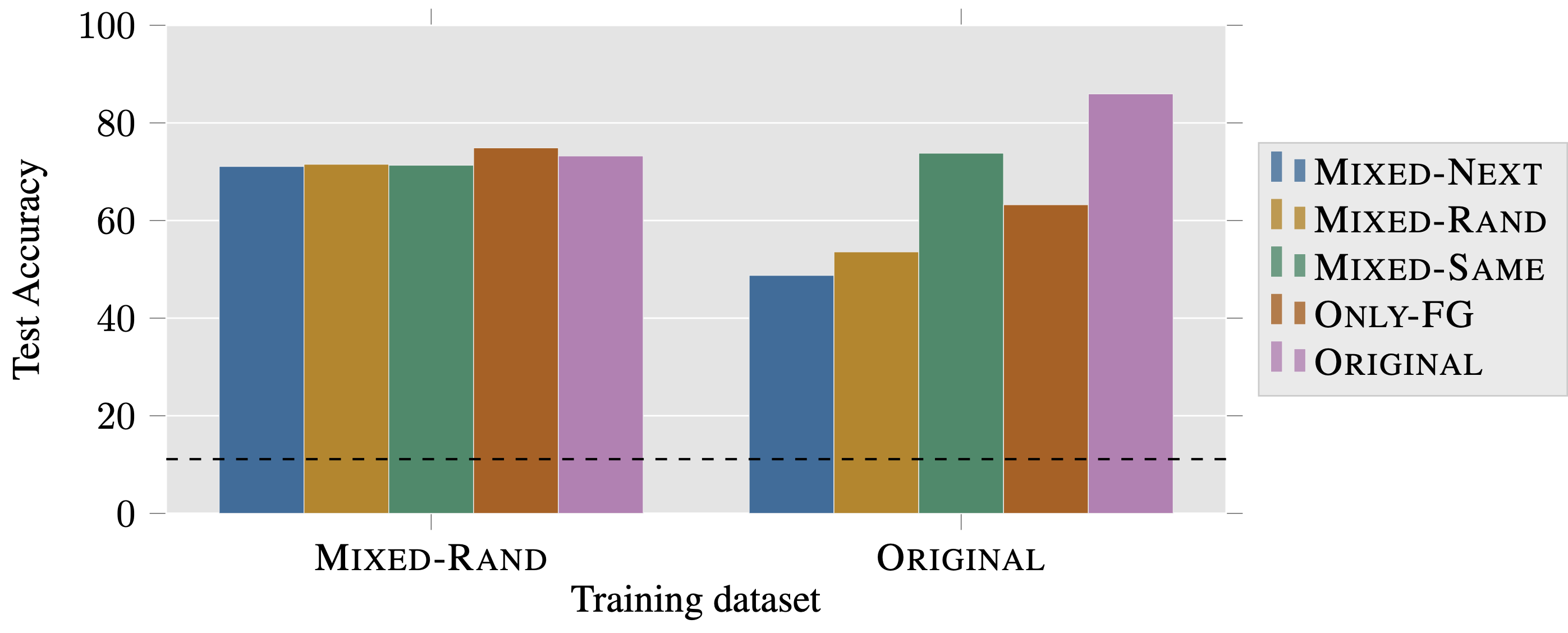
To this end, we train models on Mixed-Rand, where background signals have been
decorrelated from class labels.
We find these models perform only slightly better than
random on datasets with no foregrounds (e.g., a ResNet-50 trained on Mixed-Rand
achieves 15% accuracy on Only-BG-T and Only-BG-B).
They also perform better in the presence of misleading backgrounds:
training on Mixed-Rand improves accuracy on Mixed-Rand by 17%, and improves
accuracy on
Qualitatively, the Mixed-Rand model also appears to place more relative importance on foreground pixels than its original counterpart, as demonstrated by the saliency maps below:

5. Are we really making progress?
We’ve now shown that models can exploit backgrounds, do exploit backgrounds, and may actually do so to a fault. Considering that the development of these models is driven by standard computer vision benchmarks, our results beg the question: to what extent have improvements on ImageNet come with (or resulted from) improvements in leveraging background correlations? And relatedly, how has model robustness to misleading background signals evolved over time?
As a first step towards answering these questions, we study the progress made by ImageNet models on our proposed synthetic datasets. Below, we plot accuracy on these datasets against ImageNet accuracy for a variety of different network architectures:
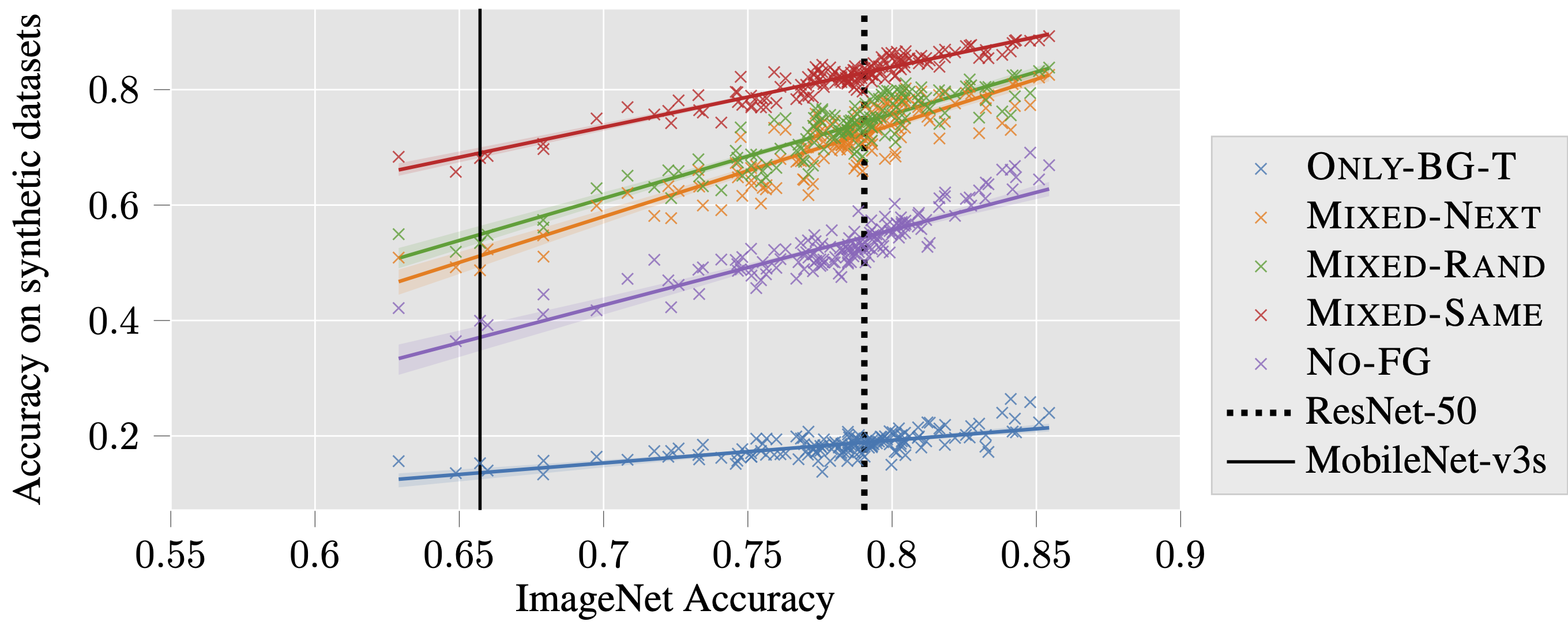
The plot indicates that accuracy increases on ImageNet generally correspond to
accuracy increases on all of the synthetic datasets that we consider.
This includes the datasets that only contain background signals (Only-BG-T
in the graph above), which means that models do improve at extracting correlations
from image backgrounds. The fact that better models are also better at
classifying background-only images suggests that the use of background
signals might be inherent to the current training paradigm, and may
not
Still, models’ relative improvement in accuracy across dataset variants is promising—accuracy on background-only datasets is improving slower than accuracy on datasets where the background is misleading, such as Mixed-Rand or Mixed-Next. Another promising sign is that the performance gap between the Mixed-Rand and Mixed-Same dataset (which we previously referred to as the BG-Gap) trends towards closing, indicating that models are not only better at using foreground features, but also more robust to misleading background features.
Overall, our analysis reveals that better models in terms of ImageNet accuracy are (a) increasingly capable of exploiting background correlations, but at the same time (b) becoming more robust to changes in background, suggesting that over-reliance on background features may not be necessary to maximize the benchmark accuracy.
Conclusions
In this post, we saw how computer vision models tend to over-rely on image backgrounds in image classification. On one hand, our findings provide more evidence that our models are not fully aligned with the human vision system. On the other hand, we have shown that advances in computer vision models, such as new architectures and training methods, have led to models that tend to use the foreground more effectively and are more robust to misleading backgrounds. We hope that the datasets and findings in this work provide a way to monitor progress towards reliable, human-aligned machine learning.
For more detailed information about the datasets we created, full experimental results, and additional analysis, see our paper!