In our new paper, we explore how closely the ImageNet benchmark aligns with the object recognition task it serves as a proxy for. We find pervasive and systematic deviations of ImageNet annotations from the ground truth, which can often be attributed to specific design choices in the data collection pipeline. These issues indicate that ImageNet accuracy alone might be insufficient to effectively gauge real model performance.
Contextualizing Progress on Benchmarks
Large-scale benchmarks are central to machine learning—they serve both as concrete targets for model development, and as proxies for assessing model performance on real-world tasks we actually care about. However, few benchmarks are perfect, and so as our models get increasingly better at them, we must also ask ourselves: to what extent is performance on existing benchmarks indicative of progress on the real-world tasks that motivate them?
In this post, we will explore this question of benchmark-task alignment in the context of the popular ImageNet object recognition dataset. Specifically, our goal is to understand how well the underlying ground truth is captured by the dataset itself—this dataset is, after all, what we consider to be the gold standard during model training and evaluation.
A sneak peak into ImageNet
The ImageNet dataset contains over a million images of objects from a thousand, quite diverse classes. Like many other benchmarks of that scale, ImageNet was not carefully curated by experts, but instead created via crowd-sourcing, without perfect quality control. So what does ImageNet data look like? Here are a few image-label pairs from the dataset:




These samples appear pretty reasonable…but are they? Actually, while these are indeed images from the dataset, the labels shown above are not their actual ImageNet labels! [Click to see the actual ImageNet labels] Still, even though not “correct” from the point of view of the ImageNet dataset, these labels do correspond to actual ImageNet classes, and appear plausible when you see them in isolation. This shows that for ImageNet images, which capture objects in diverse real-world conditions, the ImageNet label may not properly reflect the ground truth.
In our work, we dive into examining how this label misalignment actually impacts ImageNet: how often do ImageNet labels deviate from the ground truth? And how do shortcomings in these labels impact ImageNet-trained models?
Revisiting the ImageNet collection pipeline
Before going further, let’s take a look at how ImageNet was created. To build such a large dataset, the creators of ImageNet had to leverage scalable methods like automated data collection and crowd-sourcing. That is, they first selected a set of object classes (using the WordNet hierarchy), and queried various search engines to obtain a pool of candidate images. These candidate images were then verified by annotators on Mechanical Turk (MTurk) using (what we will refer to as) the Contains task: annotators were shown images retrieved for a specific class label, and were subsequently asked to select the ones that actually contain an object of this class. Only images that multiple annotators validated ended up in the final dataset.
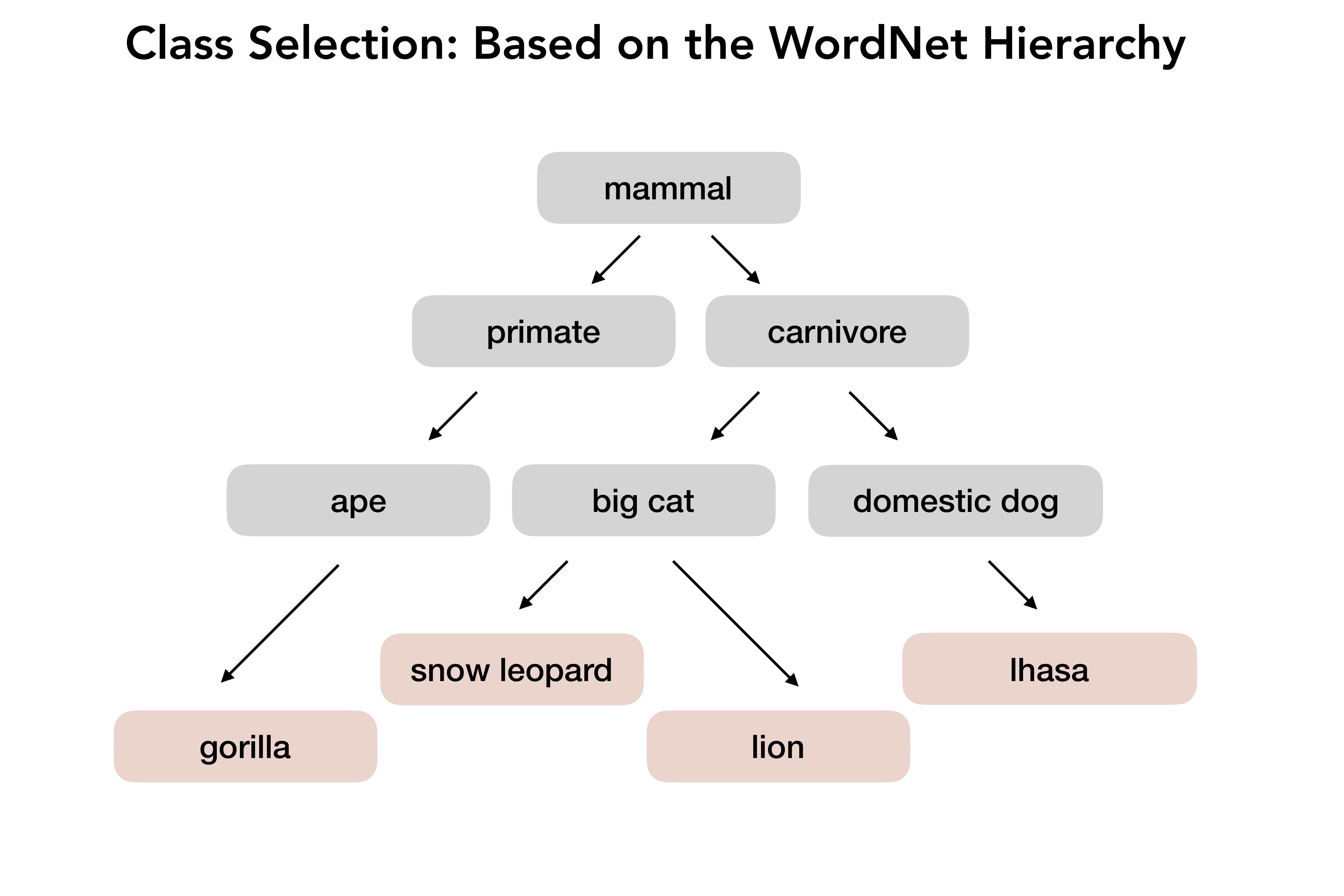
While this is a natural approach to scalably annotate data (and, in fact, is commonly used to create large-scale benchmarks—e.g., PASCAL VOC, COCO, places), it has an important caveat. Namely, this process has an inherent bias: the annotation task itself is phrased as a leading question. ImageNet annotators were not asked to provide an image label, but instead only to verify if a specific label (predetermined by the image retrieval process) was contained in an image. Annotators had no knowledge of what the other classes in the dataset even were, or the granularity at which they were required to make distinctions. In fact, they were explicitly instructed to ignore clutter and obstructions.
Looking back at the ImageNet samples shown above, one can see how this setup could lead to imperfect annotations. For instance, it is unclear if the average annotator knows the differences between a “Norwich terrier” and a “Norfolk terrier”, especially if they don’t even know that both of these (as well as 22 other terrier breeds) are valid ImageNet classes. Also, the Contains task itself might be ill-suited for annotating multi-object images—the answer to the Contains question would be yes for any object in the image that corresponds to an ImageNet class. It is not unthinkable that the same images could have made it into ImageNet under the labels “stage” and “Norwich terrier” had they come up in the search results for those classes instead.
Overall, this suggests that the labeling issues in ImageNet may go beyond just occasional annotator mistakes—the design of the data collection pipeline itself could have caused these labels to systematically deviate from the ground truth.
Diagnosing benchmark-task misalignment
To characterize how wide-spread these deviations are, we first need to get a better grasp of the ground truth for ImageNet data. In order to do this at scale, we still need to rely on crowd-sourcing. However, in contrast to the original label validation setup, we design a new annotation task based directly on image classification. Namely, we present annotators with a set of possible labels for a single image simultaneously. We then ask them to assign one label to every object in the image, and identify what they believe to be the main object. (Note that we intentionally ask for such fine-grained image annotations since, as we saw before, a single label might be inherently insufficient to capture the ground truth.)
Of course, we need to ensure that annotators can meaningfully perform this task. To this end we devise a way to narrow down the label choices they are presented with (all thousand ImageNet classes would be nearly impossible for a worker to choose between!). Specifically, for each image, we identify the most relevant labels by pooling together the top-5 predictions of a diverse set of ImageNet models and filtering them via the Contains task. Note that, by doing so, we are effectively bootstrapping the existing ImageNet labels by first using them to train models and then using model predictions to get better annotation candidates.
This is what our resulting annotation task looks like:

We aggregate the responses from multiple annotators to get per-image estimates of the number of objects in the image (along with their corresponding labels), as well as which object humans tend to view as the main one.
We collect such annotations for 10k images from the ImageNet validation set. With these more fine-grained and accurate annotations in hand, we now examine where the original ImageNet labels may fall short.
Multi-object images
The simplest way in which ImageNet labels could deviate from the ground truth is if the image contains multiple objects. So, the first thing we want to understand is: how many ImageNet images contain objects from more than one valid class?
It turns out: quite a few! Indeed, more than 20% of the images contain more than one ImageNet object. Examples:
Looking at some of these images, it is clear that the problem is not just natural image clutter but also the fact that certain objects are quite likely to co-occur in the real-world—e.g., “table lamp” and “lamp shade”. This means that choosing classes which in principle correspond to distinct objects (e.g., using WordNet) is not enough to guarantee that the corresponding images have unambiguous labels. For example, see if you can guess the ImageNet label for the samples below:
Model performance on multi-object images
So, how do models deal with images that contain multiple objects? To understand this, we evaluate a number of models (from AlexNet to EfficientNet-B7), and measure their accuracy (w.r.t. the ImageNet labels) on such images. We plot these accuracies below (as a function of their full test accuracy):
Across the board, in comparison to their performance on single-object images, models suffer around a 10% accuracy drop on multi-object ones. At the same time, this drop more-or-less disappears if we consider a model prediction to be correct if it matches the label of any valid object in the image (see the paper for specifics).
Still, even though models seem to struggle with multi-object images, they perform much better than chance (i.e., better than what one would get if they were picking the label of an object in the image at random). This makes sense when the image has a single prominent object that also matches the ImageNet label. However, for a third of all multi-object images the ImageNet label does not even match what annotators deem to be the main object in the image. Yet, even in these cases, models still successfully predict the ImageNet label (instead of what humans consider to be the right label for the image)!
Here, models seem to base their predictions on biases in the dataset which humans do not find salient. For instance, models get high accuracy on the class “pickelhaube”, even though, pickelhaubes are usually present in images with other, more salient objects, such as “military uniforms”, suggesting that ImageNet models may be overly sensitive to the presence of distinctive objects in the image. While exploiting such biases would improve ImageNet accuracy, this strategy might not translate to improved performance on object recognition in the wild. Here are a few examples that seem to exhibit a similar mismatch:
Biases in label validation
Let us now turn our attention to the ImageNet data filtering process. Recall that each class in ImageNet was constructed by automatically retrieving many images and filtering them (via the Contains task described above). How likely were annotators to filter out mislabeled images under this setup?
To understand this, we replicate the original filtering process on the existing ImageNet images. But this time, instead of only asking annotators to check if the image is valid with respect to its ImageNet label (i.e., the search query), we also try several other labels (each in isolation, with different sets of annotators).
We find that annotators frequently deem an image to be valid for many different labels—even when only one object is present. Typically, this occurs when the image is ambiguous and lacks enough context (e.g. “seashore” or “lakeshore”), or annotators are likely confused between different semantically similar labels (e.g., “assault rifle” vs. “rifle”, dog breeds). It turns out that this confusion, at least partly, stems from the one-sidedness of the Contains task—i.e., asking annotators to ascertain the validity of a specific label without them knowing about any other options. If instead we present annotators with all the relevant labels simultaneously and ask them to choose one (as we did in our annotation setup), this kind of label confusion is alleviated: annotators select significantly fewer labels in total (see our paper for details). So, even putting annotator’s expertise aside, the specific annotation task setup itself drastically affects the quality of the resulting dataset labels.
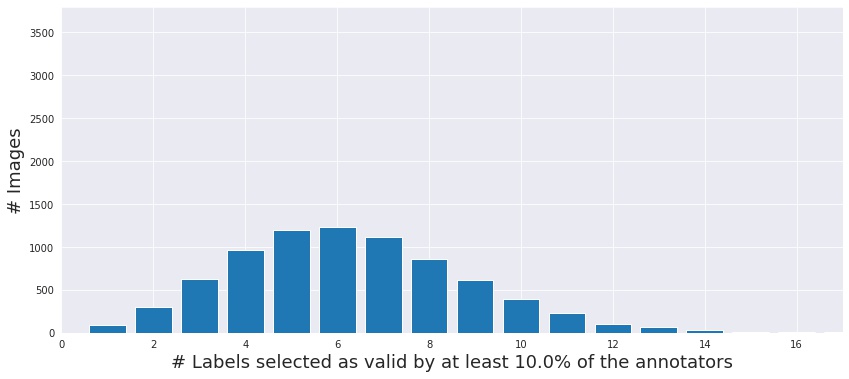
Going back to ImageNet, our findings give us reason to believe that annotators may have had a rather limited ability to correct errors in labeling. Thus, in certain cases, ImageNet labels were largely determined by the automated image retrieval process—propagating any biases or mixups this process might introduce to the final dataset.
In fact, we can actually see direct evidence of that in the ImageNet dataset—there are pairs of classes that appear to be inherently ambiguous (e.g., “laptop computer” and “notebook computer”) and neither human annotators, nor models, can tell the corresponding images apart (see below). If such class pairs actually overlap in terms of their ImageNet images, it is unclear how models can learn to separate them without memorizing specific validation examples.
Beyond test accuracy: human-centric model evaluation
Performance of ImageNet-trained models is typically judged based on their ability to predict the dataset labels—yet, as we saw above, these labels may not fully capture the ground truth. Hence, ImageNet accuracy may not reflect properly model performance—for instance, measuring accuracy alone could unfairly penalize models for certain correct predictions on multi-object images. So, how can we better assess model performance?
One approach is to measure model-human alignment directly—we present model predictions to annotators and ask them to gauge their validity:
Surprisingly, we find that for state-of-the-art models, annotators actually deem the prediction that models make to be valid about as often as the ImageNet label (even when the two do not match). Thus, recent models may be better at predicting the ground truth than their top-1 accuracy (w.r.t. the ImageNet label) would indicate.
However, this does not imply that improving ImageNet accuracy is meaningless. For instance, non-expert annotators may not be able to tell apart certain fine-grained class differences (e.g., dog breeds) and for some of these images the ImageNet label may actually match the ground truth. What it does indicate, though, is that we are at a point where it may be hard to gauge if better performance on ImageNet corresponds to actual progress or merely to exploiting idiosyncrasies of the dataset.
For further experimental details and additional results (e.g., human confusion matrices), take a look at our paper!
Conclusions
We took a closer look at how well ImageNet aligns with the real-world object recognition task—even though ImageNet is used extensively, we rarely question whether its labels actually reflect the ground truth. We saw that oftentimes ImageNet labels do not fully capture image content—e.g., many images have multiple (ImageNet) objects and there are classes that are inherently ambiguous. As a result, models trained using these labels as ground truth end up learning unintended biases and confusions.
Our analysis indicates that when creating datasets we must be aware of (and try to mitigate) ways in which scalable data collection practices can skew the corresponding annotations (see our previous post for another example of such a skew). Finally, given that such imperfections in our datasets could be inevitable, we also need to think about how to reliably assess model performance in their presence.