Suppose we want to train a classifier to distinguish between dogs and cats given a labeled dataset of photos. Having read about the perils of training on biased or otherwise suboptimal data, we comb through our collection of labeled images and carefully eliminate problems like spurious correlations or under-represented subgroups. So, for example, finding that most cats in the dataset were photographed indoors while most dogs were photographed outdoors, we collect more outdoor cat photos and indoor dog photos.
The result is a carefully curated dataset that we can now use to train our classifier. Unfortunately, there is a problem: our dataset is small, so training on it yields a poorly performing model. But, fortunately, we know what to do! To get a better classifier, we go online and download (or pay for) a pre-trained model, i.e., a model that’s been trained on a much larger dataset like ImageNet-1K or JFT-300. We’ll then use transfer learning to adapt this pre-trained model (the “source model”) to our dataset (the “target dataset”). Transfer learning from a pre-trained model in this way results in a model that performs much better on our target task than one trained on it from scratch.
This seems like great news—we get a much better performance at little cost! But there is a potential wrinkle: pre-trained models turn out to have a variety of undesirable biases. For example, they can disproportionately rely on texture, on image background, or on object location/orientation. These biases even arise in production-level pretrained models—Amazon’s Rekognition, for example, performs disparately across races and genders. Could these biases show up in our target model, despite our careful curation of our target dataset?
In our most recent work, we find that biases from pre-trained models indeed tend to “transfer”, i.e., they can manifest themselves in the resulting model. In particular, we study this “bias transfer” through the lens of the following questions:
- When can bias transfer happen? What is the effect of the pre-training dataset, the transfer learning algorithm, and the target dataset on this bias transfer? Moreover, can we avoid bias transfer altogether by intervening on our target dataset?
- Does bias transfer actually happen in practice? For example, suppose we pre-train a model on the ImageNet-1K dataset and use transfer learning to adapt it to CIFAR-10. Can we pinpoint concrete biases of the resulting model that are not present when we train on CIFAR-10 from scratch?
We’ll dive into some of these questions below (see our paper for a more thorough treatment).
(When) does bias transfer occur?
Let us consider a simple experiment. We take the ImageNet-1K dataset (a popular pre-training dataset for transfer learning), and add a small yellow square to every image of a dog in its training set:

As expected, training on this dataset yields a model that is highly sensitive to the presence of yellow squares. Indeed, when the yellow square is planted on images of other (non-dog) objects, the model predicts a dog class 44% of the time (as opposed to 2% for a standard ImageNet model)!
We now want to use this yellow square sensitivity as a (simple) example of a bias in a pre-trained model. Specifically, to study the possibility of bias transfer, we apply transfer learning to obtain models for a variety of target tasks using both this biased model and a standard ImageNet model as the point of start. We then examine whether transfer learning from the biased model leads to a significantly higher sensitivity to yellow squares. (Note that none of the target datasets have any of these yellow squares at all.)

As we find, models that are transferred from the biased pre-trained network were significantly more sensitive to the presence of our yellow square. This happened consistently across two transfer learning techniques (fixed-feature and full-network transfer learning) and a variety of datasets we considered. For example, below, we plot the attack success rate (ASR)—the probability that introducing a yellow square into a random image will flip a model’s prediction—for models transferred from both the biased (Spurious) model and standard (Non-Spurious) model:
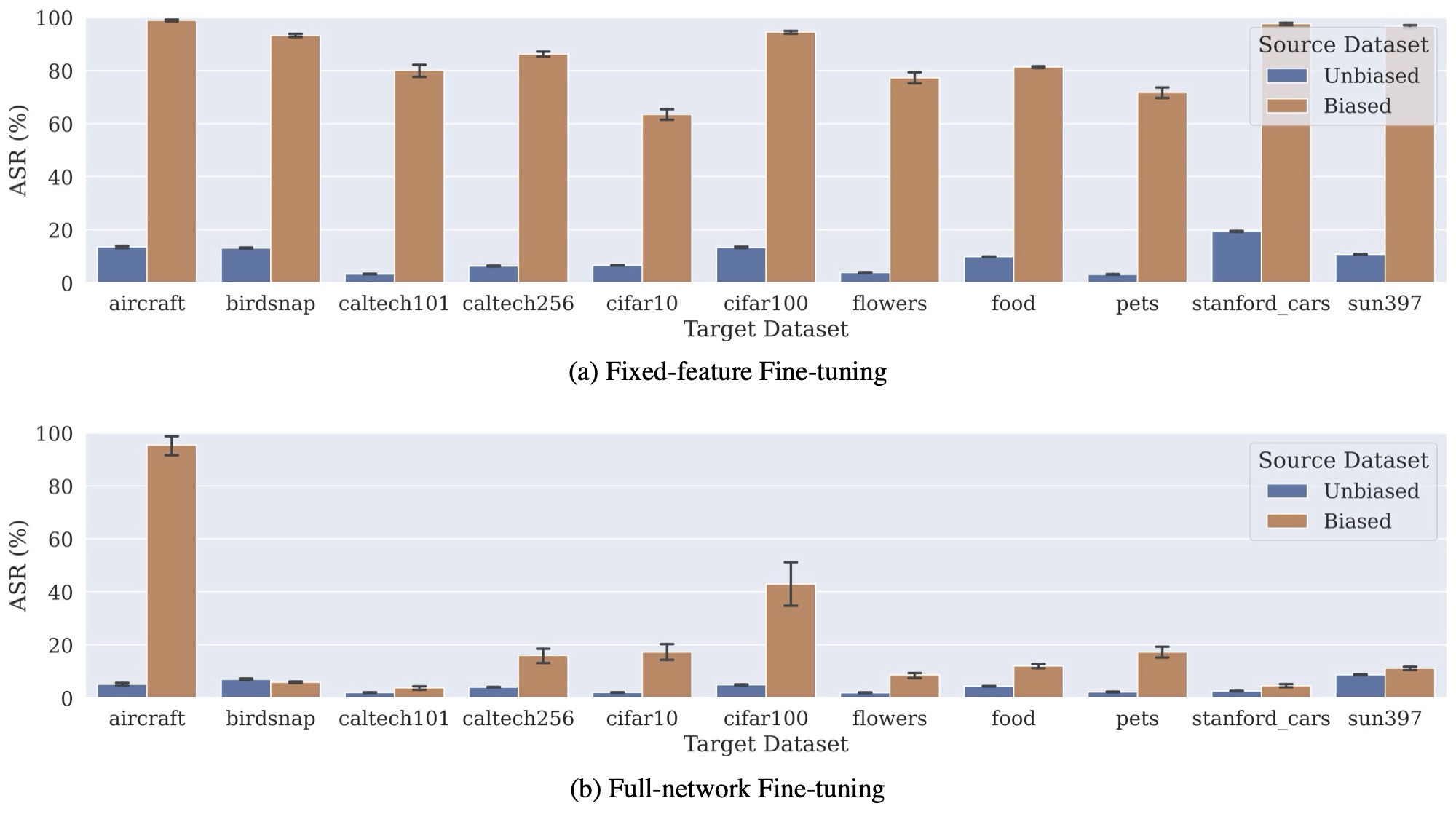
However, what happens if we try to more carefully design the target dataset to specifically counter bias transfer? For example, if in this case we’re worried that our pre-trained model has a bias associating the yellow square with the “dog” classes, we might put an extra effort and alter the target dataset to make sure that (a) the yellow square is also present in some of the images but (b) its presence is not correlated with any of the classes. So, is using such a “de-biased” target dataset enough to avoid bias transfer?
Turns out that the answer is: it depends! Specifically, we find that when using a particular kind of transfer learning (full-network transfer learning), adding the backdoor trigger to the target dataset indeed mitigates bias transfer. However, when using the fixed-feature transfer learning, the transferred model still contains the bias—even when 10% of the target dataset contains (uncorrelated) yellow squares.
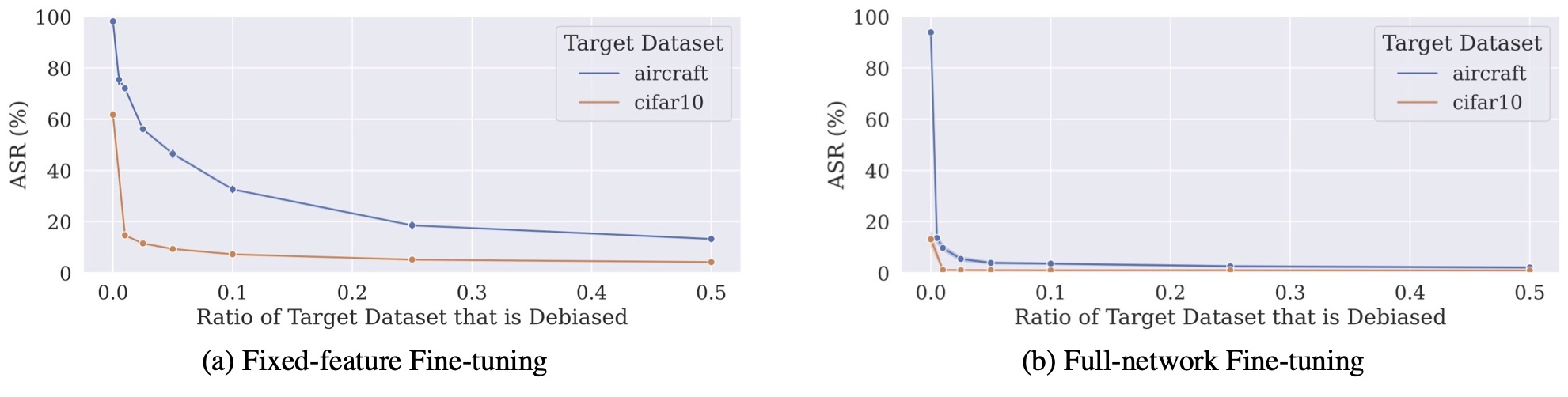
So overall, not only does bias transfer across various datasets and transfer learning settings, it also might be non-trivial (at least in the fixed-feature transfer learning setting) to remedy this bias transfer even when we are aware of the possibility of that bias and try to explicitly de-bias the target dataset.
Bias Transfer in the Wild
Ok, so we know now that bias transfer can happen—at least when there’s a significant bias planted in the source pre-trained model. But in practice, source datasets will rarely have a feature as consistent and predictive as a planted yellow square we considered above. Can biases naturally occurring in common image datasets transfer as well?
It turns out that the answer here is: yes, too! For instance, let’s consider a (rather unsurprising) bias arising in the widely-used ImageNet dataset: a circular yellow shape is predictive for the “tennis ball” class. (See our paper for many other examples and datasets.) Indeed, as we can see below, if we overlay a yellow circle on any ImageNet image, the model becomes more likely to output “tennis ball:”
Now, what happens if we use transfer learning to obtain a model for a target task, such as CIFAR-10 from a pre-trained ImageNet model containing this yellow circle -> “tennis ball” bias? Even though CIFAR-10 does not contain the yellow circle -> “tennis ball” bias, this bias still persists in the resulting transfer-learned model! In particular, when we evaluate our model on CIFAR-10 test set images overlaid with a yellow circle, the model fine-tuned from a pre-trained ImageNet model is far more sensitive to that signal than a CIFAR-10 model trained from scratch. Indeed, there is an overall skew of the output class distribution for the transfer-learned model, in contrast to an almost uniform output class distribution of the model trained from scratch.
Conclusions
In this post, we discussed our recent work that demonstrates that biases that exist in pretrained models can persist even if these models are adapted to target datasets which do not contain these biases. It is thus important to understand the biases of the pre-trained models one uses for transfer learning, even if the task these models were pre-trained on do not seem relevant to the target task we want to solve. This prudence is particularly key in the context of high-stakes real-world machine learning applications that often suffer from data scarcity and tend to use transfer learning as a remedy for that.