In our new paper, we develop a framework for simulating realistic subpopulation shifts between training and deployment conditions for machine learning models. Evaluating standard models on the resulting benchmarks reveals that these models are highly sensitive to such shifts. Moreover, training models to be invariant to existing families of synthetic data perturbations falls short of remedying this issue.
Consider what is probably the most prototypical classification task: distinguishing between pictures of dogs and cats. By now, we have a fairly established approach to tackling this task. It involves sourcing a set of (labeled) cat and dog pictures and then training our model on that set. Intuitively, we understand that for this approach to succeed our training set has to be sufficiently large and diverse, capturing a variety of real-world conditions. In particular, one might want to make sure that it contains representatives of many of the possible breeds of dogs and cats. Is it critical though that all breeds are represented? That is, if our classifier truly learns how to distinguish dogs from cats, wouldn’t we expect it to generalize to unseen breeds as well?
This is just an illustration of a broader challenge: building ML models that are robust to subpopulation shift, i.e., they are able to generalize to data subpopulations that were not encountered during training. This notion of robustness is essential for models to perform reliably in the real world. After all, we cannot expect our training set to capture all possible subpopulation variations it can encounter during deployment. (Think of, e.g., differences in weather/road conditions in the context of self-driving cars, or variability in diagnostic equipment and patients’s exact characteristics in the context of medical applications.)
Tackling subpopulation shifts
To make progress on this challenge, we need to first develop a principled way to measure such robustness (or lack thereof). So, how can we measure the extent to which our models are robust to such train-test subpopulation shifts?
A natural approach would be to first partition the subpopulations present in data for each class (e.g., dog or cat breeds) into two disjoint sets: one set that is used for training the model, and one set that is held-out for evaluation. Then, one can just examine the performance of the model on the held-out data.
This setup ensures that the actual task remains unchanged between training and testing—i.e., classifying inputs into the original classes (“dog” vs. “cat”). Therefore, the observed performance can give us a sense how well that model will perform when exposed to novel data subpopulations encountered during deployment.
The chief difficulty in implementing this strategy, however, is that standard datasets do not contain annotations that are fine-grained enough to identify the subpopulations of interest. Also, rectifying this issue by collecting additional human annotations would be complicated (not every class lends itself to identifying a natural and explicit subpopulation structure) and costly (due to the scale of state-of-the-art classification datasets).
In this post, we will outline an approach that circumvents some of the aforementioned issues, allowing us to automatically construct a suite of subpopulation shift benchmarks of varying difficulty, with minimal effort.
The Breeds methodology
Our approach is to simulate class subpopulations by grouping semantically similar classes into superclasses (e.g., aggregate the 100+ dog breed classes in ImageNet into a “dog superclass”). Then, considering the classification task over such superclasses enables us to repurpose the original dataset annotations as explicit indicators of the subpopulation structure. Note that this new task is entirely based on existing datasets, so we do not need to deal with, gathering new data points or annotations, hence avoiding the additional biases these might introduce (see our previous posts on dataset replication and annotation pipelines).
After this task restructuring, we can train our model on the resulting superclass classification task while having full control over which subpopulations are included in training and which subpopulations are encountered during testing. For example, if our original dataset contains classes: Labrador, Husky, Tabby cat, and Persian cat, which we group into “dog” and “cat” superclasses as [Labrador, Husky] and [Tabby cat, Persian cat], we can train a model on the Labrador vs. Tabby cat task and test how well it can distinguish Huskies from Persian cats. (Note that this framework can also naturally incorporate milder subpopulation shifts where test subpopulations are underrepresented, but not entirely missing, in the training set—see here.) Pictorially:
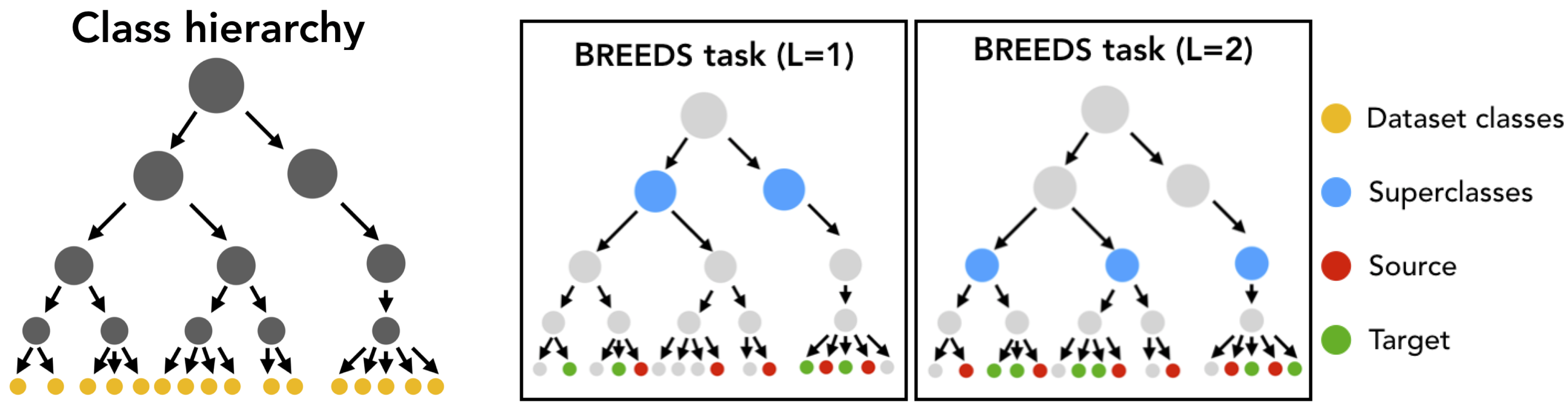
The dog vs. cat breeds example served as the motivation for our framework (as well as its name), but the underlying principle is quite general. In fact, we can (and do) apply this methodology to group together a wide variety of classes that share similar characteristics.
Obtaining meaningful superclasses
In order for such a “breeds” benchmark be tractable from an image classification viewpoint, we need to ensure that the classes we group together into superclasses actually share visual characteristics. (After all, we cannot expect a model to generalize across an arbitrary train-test partition of classes). Ideally, we would group dataset classes based on a hierarchy that captures their visual similarity—thus, allowing us to construct superclasses of varying granularity (which would lead to benchmarks of varying difficulty).
From this point of view, the ImageNet dataset is a natural candidate for building our benchmarks—aside from its breadth and scale, it also comes equipped with a class hierarchy, i.e., the WordNet hierarchy. However, taking a closer look at that hierarchy reveals a few important shortcomings: (a) classes are grouped together based on abstract (as opposed to visual) characteristics (e.g., “umbrella” and “roof” are both “coverings); (b) nodes at the same level of the hierarchy can have vastly different granularity (e.g., “street sign” and “living thing”), not necessarily mirroring the specificity of the class itself; and (c) the hierarchy is not a tree (e.g., “bread” is in both “starches” and “baked goods”). Grouping ImageNet classes based on this hierarchy would thus result in poorly calibrated tasks.
All these shortcomings stem from the fact that WordNet is a semantic rather than visual hierarchy—words are grouped together based on their meaning rather than the visual appearance of the objects they correspond to. To remedy this, we performed extensive edits to the existing ImageNet class hierarchy to better capture visual object similarity. Specifically, we removed all abstract nodes (e.g., “covering”) and calibrated the depth to ensure that nodes at the same level have comparable granularity (by adding/removing redundant nodes)—the modified hierarchy can be explored here or through the notebook we provide in the code repo.
Constructing Breeds benchmarks
Equipped with such a modified class hierarchy, we can construct subpopulation shift benchmarks of varying difficulty in an essentially automated manner: we simply choose a level of the hierarchy and treat each node at that level as a superclass. The original dataset classes that are descendants of this node then become the subclasses or “breeds”. These subclasses are then split randomly into two groups—one of these is used to sample training data points (source domain), and the other to sample test data points (target domain).
By varying the level in the hierarchy of the superclasses we select, we can create an entire suite of benchmarks. For our analysis below, we will use the following benchmarks. (You can find more details in our paper and interactively browse the hierarchy here).
Validating the benchmarks using human annotation
As already discussed, to ensure that the benchmarks we create are actually meaningful, we need to validate that the superclasses therein contain visually coherent subpopulations, so that good cross-subpopulation generalization is possible. To this end, we leverage human annotators to measure the robustness of humans to the subpopulation shifts encapsulated by (simplified versions of) Breeds tasks. Specifically, we randomly pick pairs of superclasses and then show annotators two groups of images corresponding to samples from the source domain of the respective superclasses. Then, we present them with random images from the target domain of both superclasses (mixed together) and ask them to assign these images to one of the two groups (superclasses). Crucially, we do not reveal to the annotators the name of either of the superclasses. Here is what the task looks like:

If our superclasses are indeed well-calibrated for the task, annotators should be able to associate new images with the correct group. That is, images from the target domain of a superclass should be more similar to the source domain of the same superclass, rather than the other one. Also, to establish a baseline, we repeat the same experiment while asking the annotators to classify unseen samples from the source domain (i.e., when there is no subpopulation shift).
So how well do our annotators perform?
As we can see, the difference in average annotator accuracy (in terms of classifying unseen inputs into the correct group/superclass) between the source and target domain is quite small. This suggests that the superclasses do indeed correspond to visually meaningful object groupings, and, moreover, that humans are quite robust to the distribution shifts captured within the Breeds tasks. Let us now compare this drop to the one that our models incur.
Subpopulation robustness of standard models
To assess whether standard models are sensitive to subpopulation shifts, we will, for each Breeds task, train a number of standard architectures to distinguish between the corresponding superclasses, using data from the source domain and then measure model performance on data from the target domain. Specifically, we will plot the target accuracy of each model as a function of its source accuracy.
Across the board, all models suffer a clear drop in performance under subpopulation shifts—-accuracy drops by more than 30 percentage points between the source and target domains. This indicates that the features models rely on to perform well are somewhat specific to the subpopulations they encounter during training, and thus tend to lose their predictive power even under seemingly mild shifts in test-time subpopulations. [CLICK THIS to compare model performance to that of human annotators.]
A natural question to ask then is: can these models be adapted to the target domain by simply re-training their last layer with data from this domain? [CLICK THIS to add the re-training line.] The answer seems to be nuanced. On one hand, re-training significantly increases model performance, indicating that the representations learned in the earlier layers of these (source-domain trained) models are useful also for the subpopulations in the target domain. On the other hand, these representations still fall short of what one would hope for—the target accuracy post retraining remains much lower than that of a model trained directly on the target domain.
Robustness interventions
Given that standard models turned out to be very sensitive to subpopulation shifts, one might hope that applying a number of existing robustness interventions—designed to increase model robustness to specific synthetic perturbations—might change this state of affairs. To assess this, we evaluate the subpopulation shift robustness of classifiers that have been trained: (a) via robust optimization against L2 adversaries of different epsilon; (b) on a stylized version of ImageNet (relying less on texture and thus more on shape); and (c) with random noise (Gaussian or Erase).
To control for the significant impact on the standard (source) accuracy that these methods can have, we focus on the relative target accuracy of the resulting models—that is the fraction of accuracy that is preserved in the target domain (target accuracy over source accuracy).
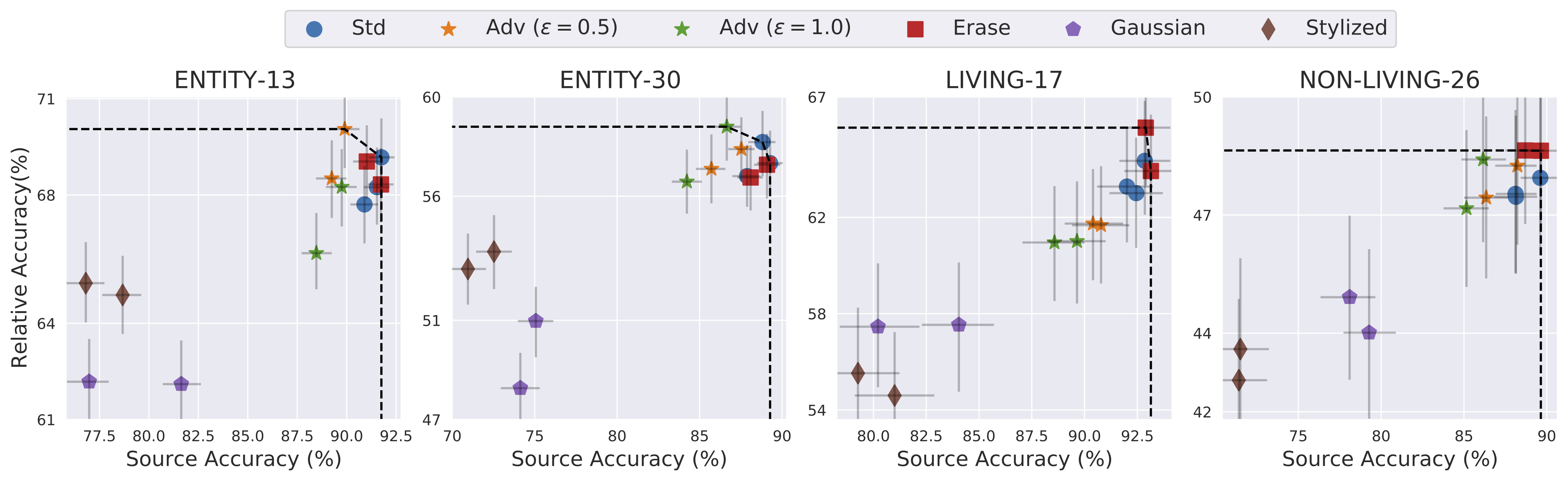
We observe that these robustness interventions do have an impact on the target accuracy of the model. Moreover, even when the resulting models have comparable source accuracies, their target accuracies can be quite different. For instance, erase noise improves robustness without particularly impacting source accuracy (relative to standard models), while adversarially trained models improve robustness at the expense of source accuracy. Overall, these results indicate that while existing interventions make models slightly less sensitive to subpopulation shifts, there is still significant room for improvement.
To obtain a more complete picture, we also measure the performance of the above models after retraining the final layer with data from the target domain. Again, our goal is to understand whether the employed training methods lead to representations that are more general, and can be directly repurposed for the target domain.
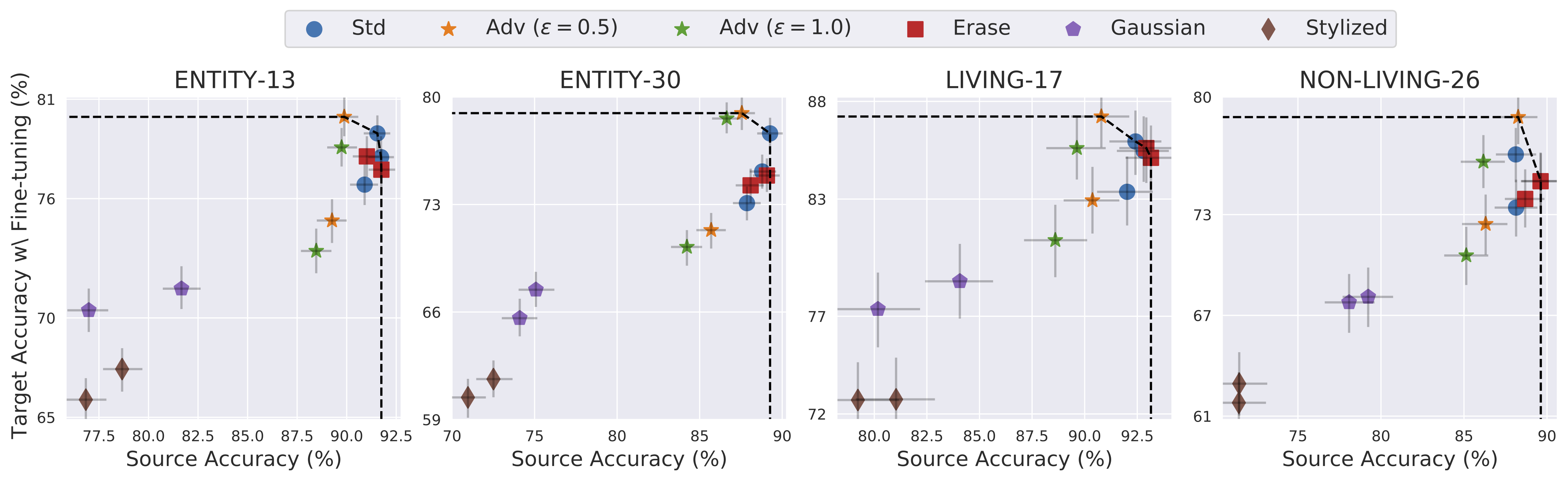
Interestingly, we see that models trained with erase noise are not better than standard models after we allow for such fine-tuning. This indicates that the gain in robustness it provides may not stem from learning better representations. In contrast, adversarially trained models are significantly better than other models (including standard ones) after fine-tuning. This is in line with recent results showing that adversarially trained models are more suited for transfer learning (here and here). At the same time, models trained on the stylized version of ImageNet are consistently worse than other models, even relative to models with similar source accuracy. This could indicate that texture is a particularly useful feature for this classification task, especially in the presence of subpopulation shift.
Conclusions
In this post, we demonstrate how one can utilize a class hierarchy to simulate a range of subpopulation shifts within existing classification datasets. These shifts turn out to pose a challenge for standard models (seemingly more so than for humans) and this challenge cannot really be overcome using existing robustness interventions or re-training the last layer. Thus, there is a need for designing new methods to address this core robustness requirement. Overall, we believe that subpopulation shifts are an important piece of the robustness puzzle and we hope that the benchmarks we develop will serve as a guide for future progress on this front.