tl;dr: When training large-scale models, standard practice is to select training data that is intuitively useful. However, it turns out that such data can actually hurt model performance. We instead design a framework that selects by modeling how models learn from data—and thereby greatly improve performance.
Suppose we want to train a large-scale ML model, like a language model or a diffusion model. How do we choose which data to train on? Standard methods tend to select data using human notions of data quality. For example, the GPT-3 training procedure selects training data that matches intuitively “high quality” data sources like Wikipedia. Filtering like this yields (qualitatively) clean data that feels like it should improve model performance. But does it actually improve performance in practice?
Comparing with the simplest possible dataset selection method, randomly choosing data, it turns out that the exact opposite can happen. Training one language model on data selected with GPT-3’s method, then training another model on randomly chosen data, we find that the latter model performs better!
How is this possible? To try to understand, let’s take a brief detour to the red planet…
Martians and humans do not learn the same way
 [modified from image source]
[modified from image source]
Suppose Earth has just contacted Martians, and that you need to teach them English. You fly to Mars bringing as many documents as you can fit on a spaceship and upon arrival you start trying to teach.
You try first teaching them to read kindergarten level books, then first grade books, and so on—but the aliens learn from the books you give them at a snail’s pace. What works for teaching humans does not seem to work on the aliens! You are able to eventually teach the aliens to read, but only by chancing upon documents that the aliens seem to respond to.
Little do you know, Martians can actually learn English from documents very well, but hate even numbers: they get too upset to learn if documents have an even number of words! Hopefully you will figure this rule out for next time.
Machine learning models are martians
We haven’t (yet) made contact with aliens, but this story matches how we currently choose data for machine learning models. Standard methods choose training samples according to human notions of quality, but ideally we would choose training samples that most improve model learning. Indeed, as we showed above, intuitively useful data does not always aid model performance in practice.
Framing dataset selection
To develop better methods for selecting data, we start from first principles. That is, we avoid intuitive notions of data quality, and instead frame dataset selection as an optimization problem where the goal is to—given target tasks, a learning algorithm, and a candidate data pool—select the data that maximizes trained model performance.
However, finding the optimal solution to this problem is intractable. After all, in ML we usually maximize model performance with respect to parameters, not training dataset choice! While maximizing with respect to parameters is relatively straightforward (just descend the gradient!), there are no known (efficient) methods for directly optimizing model performance with respect to training set choice. In general, it is unclear how to calculate the best possible training subset without training a model on each possible subset one by one and checking for the best performing model—which is far too expensive.

Approximating the optimal dataset selection with DsDm
We can’t directly solve this computational problem, but we can approximate the optimal training data subset using datamodels. Datamodels are a framework designed for efficiently approximating the mapping between training subset and model performance (see our paper for more details!).
Our resulting estimator, DsDm, or Dataset Selection with Datamodels, consistently selects training data subsets that improve performance on language modeling target tasks. To evaluate DsDm on a given target task, we select subsets of the candidate dataset (C4, a common web-scrape), then train models and test on that specific task. Below, we plot the size of the selected dataset on the x-axis against task performance on the y-axis (larger is better, each subplot shows performance on a single task):

Here, randomly selecting data turns out to be a surprisingly strong baseline. Standard targeted dataset selection methods—which choose data according to textual similarity with the target tasks (DSIR and Classifier, our name for the classification-based method used to select the GPT-3 training dataset)—do not reliably outperform selecting data randomly (e.g., on SQuAD, a reading comprehension benchmark, and CS Algorithms, an algorithmic problem solving dataset).
In contrast, DsDm (in blue) consistently improves target task performance on all target tasks. DsDm even outperforms a much larger model (10x compute) trained on randomly selected data (dotted red line)!
Case study: given a target task, the most useful data ≠ textually similar data
What characterizes the best training data? To investigate, we inspect the data selected by each method:
2. ises; soldier of fortune.\n3. a person who undertakes great commercial risk; speculator.\n4. a person who seeks power, wealth, or social rank by unscrupulous or questionable means: They thought John was an adventurer and after their daughter’s money.\n"There can be adventurer souls."\n"There can be adventurer sirs."\n"There can be adventurer reflexes."\n"There can be adventurer realises."\n"There can be adventurer profiles."\n"There can be adventurer problems."\n"There can be adventurer paths."\n"There
DsDm text
2. their professional careers.\nDr Simpson’s first line is classic.\nlatest date in the year it’s been that cold in 50 years of record keeping.\nBack in March, 2007, Al Gore told Congress that "the science is settled."\nscience is settled. The Sun revolves around the Earth, not vice versa.\nscience," spent the rest of his life under house arrest.\n& Tax Bill (its actual name) through the House? Hopefully, some "cooler"\nseem, may have nothing to do with global warming.\nPaul, let me give you a little advice.\nYou migh
Classifier text
Improving performance on unseen tasks
We’ve seen that DsDm can improve performance on pre-specified tasks. However, in practice we train large-scale models to perform well on unseen tasks. Our framework suggests a principled approach in this scenario as well: choose tasks representative of those that we expect to see at deployment-time, then use DsDm to select training data that maximizes performance on these tasks.
To demonstrate the effectiveness of this approach, we target DsDM towards three tasks that are broadly representative of standard language modeling problems (Jeopardy, LAMBADA, and SQuAD) and select data from C4. Below, we train models with varying compute budgets, and plot the compute budget on the x-axis against the mean benchmark accuracy (on 15 standard benchmarks) on the y-axis:
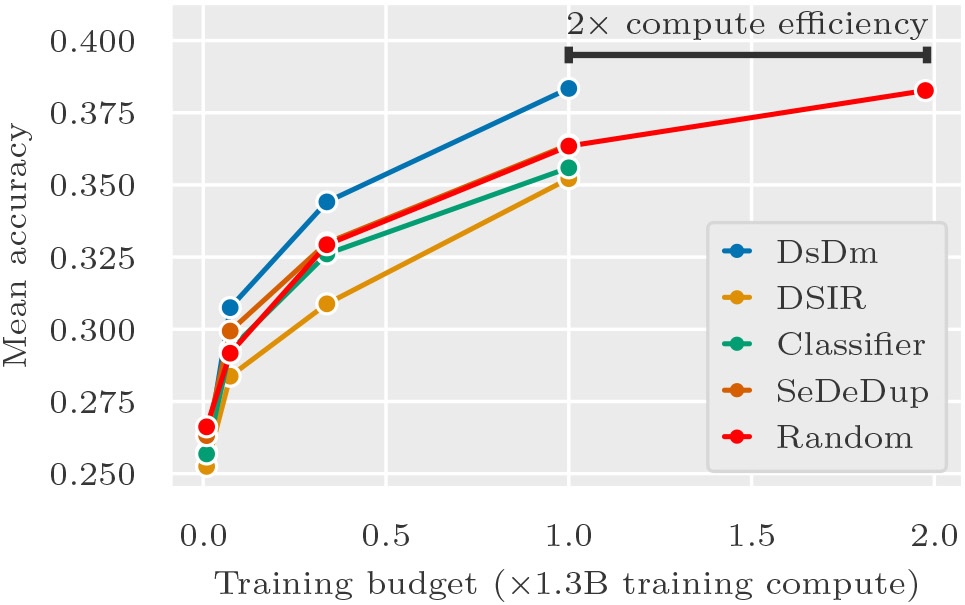
At every compute budget, models trained with baseline methods that select according to intuitive notions of data quality at best match, and mostly underperform, models trained with randomly selected data.
In contrast, our method is a 2x compute multiplier! Models trained with DsDm match larger models trained on random-selected data with twice the total compute budget.
Conclusion
Looking beyond increasing model performance, our framework unlocks dataset selection as a tool for controlling model behavior in a fine-grained manner. That is, we believe optimizing over dataset selection can not only improve model performance, but also improve any other downstream property of our trained models, e.g., a given notion of fairness or alignment with human preferences. We are also excited about applications around selecting data for more specialized capabilities arising in context, e.g., low-resource languages or domain-specific tasks like computer programming.
Read more in our paper! Please leave any comments below, and don’t hesitate to contact us.