In our recent work, we develop a framework for modifying the behavior of a classifier by directly rewriting its internal prediction rules. This allows a model designer to adapt the model to new setting or remove specific spurious correlations with virtually no additional data collection or further model training.
Motivation
Modern machine learning classifiers work because they are able to extract predictive correlations from large, relatively uncurated datasets. However, as has been pointed out re-pea-te-dly, many of these correlations are spurious or context-specific. That is, while they are predictive on the training dataset, they need not necessarily be predictive in the real-world settings where we wish to deploy our models. For instance, a useful example to keep in mind throughout this post is that of “cars on snow”: if a model relies on the presence of “road” to recognize a car (because most cars in the training set are on the road) it might have trouble recognizing cars when they drive through snow.
So, what can we do about that?
Editing classifiers: Setting up the problem
A natural idea is to modify the model after training, but how exactly would we do that? The canonical method for modifying such a “buggy” ML model once it has been trained is to collect additional data that captures the classifier’s intended behavior and then use that data to fine-tune the model. However, collecting such data might be tricky and/or expensive. More importantly, this is an indirect process, i.e., we are specifying model behavior only through training examples—which is what gave rise to undesired correlations in the first place.
In order to develop a more reliable process, we want to allow a model designer to directly edit model’s “inner mechanics”. In other words, we want the designer to be able to specify how a model should predict on broad families of inputs (and not just what it should predict on a specific, fixed set of training inputs).
Conceptually, we can think of the model as operating based on some prediction rules. For instance, “if grass is present, then this is likely an image of a cow” or “if a wheel is present, this is likely an image of a car”. From that perspective, our goal is to enable the designer to interact with these rules and rewrite how these concepts (e.g., “car”, “wheel”) are associated with each other. Crucially, we need for such rewrites to generalize, i.e., if one modifies how the concept “wheel” is perceived by the model, then this modification should apply to all instances containing a wheel.
A concrete editing methodology
So, how do we turn this conceptual framework into an actual tool? Our method—which we will describe now—builds on the recent work of Bau et al. 2020 that developed a method for editing generative models.
Concepts as vectors. Our point of start is figuring out a way to capture high-level concepts via concrete objects that we can manipulate. The object of choice is latent vectors. Indeed, as it turns out, it is possible to find directions in the latent representation of the model that capture different visual concepts (e.g., TCAV or Network Dissection). Moreover, as Bau et al. found, it is possible to find such directions based only on a few images. This can be done by simply selecting the pixels corresponding to the desired concept and then aggregating the latent representations of these pixels via PCA.
Layers as associative memory. Next, we want to develop a way to modify how the classifier processes these high-level concepts (captured by vectors). For this, we view each layer of the network as a linear associative memory: i.e., a mapping of each latent vector in its input (the key) to another latent vector in its output—the value. From that perspective, if we have a vector $k$ capturing some high-level concept in the latent representation space before some layer $L$, and a vector $v$ capturing another concept after $L$, then we can modify the weights $W$ of that layer to map one concept to another, i.e., have that
\[v \simeq Wk.\]Importantly, to ensure that this update does not affect how other concepts are being processed, we restrict it to only a rank-one change in the weights W. You can find a more detailed description in the original paper.
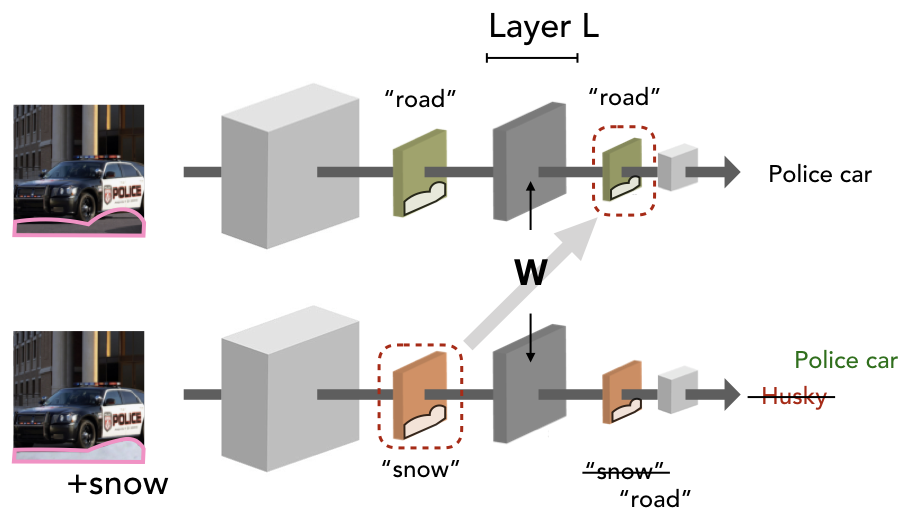
Rewriting classifiers. With these primitives in place, we can focus our attention on editing classifiers. How would we modify a model to recognize cars on snow as it would if they were on the road? At a high-level, we need to ensure that the model treats the concept of “snow” the same way it treats the concept of “road”. To this end, we start from a picture of a car (on a road), manually annotate the part that depicts “road”, and then replace this part by copy-pasting a snow texture on it.
Now, fixing any layer $L$, we use the selected pixels to compute a “snow” vector $k$ before that layer and a “road” vector $v$ after that layer. Then, in order to perform our edit we simply update the weights of that layer so that it (approximately) maps the vector $k$ to the vector $v$. And that’s it! We can leave the rest of the model as-is, since the snowy part of the image will be processed as if it depicted a road.
Does editing work?
Let’s now try to apply this methodology to a couple of real world test cases. In both cases, we will perform these updates based on a single exemplar that we manually modified.
Scenario 1: Vehicles on snow. We start with our running example of vehicles-on-snow. For that, we form a test set through searching Flickr for images of “<vehicle> on snow” for a number of different vehicles corresponding to ImageNet classes. We observe that the performance of our ImageNet model on these new images is not great. Can we now improve the model on this test set via a targeted edit?

To check that, we form an exemplar by taking a picture of a “police van” (a class that is not in our test set) on a road and replacing the road with a snow texture. It turns out that by then editing the model to map “snow” to “road” using our method we can indeed improve the performance on our snowy test set! Also, note that the vehicle in our exemplar belongs to a class that is not part of the test set, so we can see that our edit generalized to other instances of the concepts used.
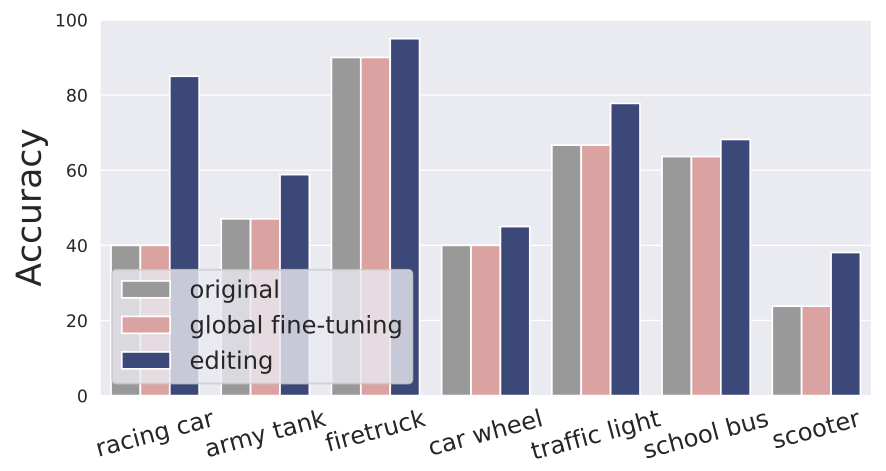
It is worth contrasting this with the performance of fine-tuning, i.e., when we simply fine-tune the whole model on this exemplar. There seems to be no performance improvement in this case.
Scenario 2: Typographic-attacks. We then take a look at the recent typographic attacks of [Goh et al., 2021]: putting a handwritten “ipod” label on different household objects causes a CLIP classifier to classify them as iPods! Here is our reproduction:

Now, we will try to edit this classifier to make it ignore this misleading text and thus predict the underlying object correctly. To do so, we start from an unrelated image of a can opener and synthetically create two version of that image: one where we paste an “ipod” label and one where we paste a blank label. We then edit the model to map “ipod” to “blank” and we find that this corrects the model predictions on all images, making the model impervious to this typographic-attack!

In contrast, fine-tuning is not a reliable solution. While it can fix some mistakes (potentially by adjusting class biases), it often causes the model to incorrectly associate other objects with the fine-tuning label and/or decreases model performance on actual ipod images.
Large-scale synthetic evaluation
While the two examples that we looked at so far might be compelling, we want to stress test our method on a wider variety of settings. Unfortunately, manually identifying interesting scenarios and collecting the corresponding datasets is a daunting task. We thus focus on creating synthetic editing test cases.
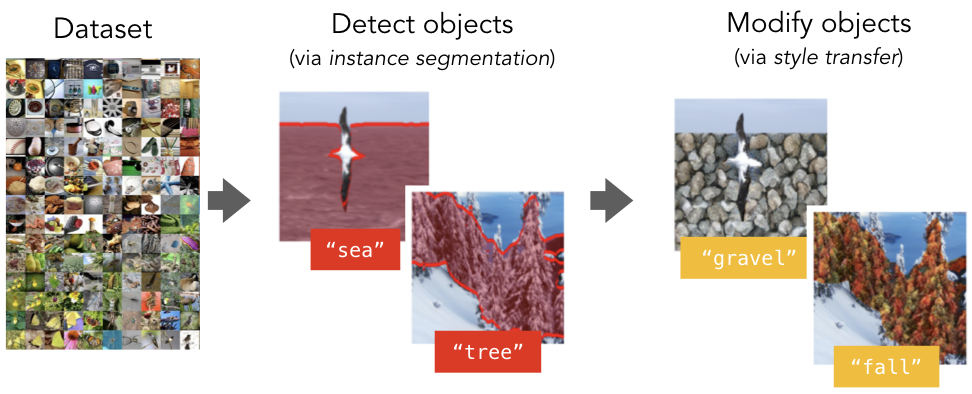
Specifically, we want to setup scenarios in which we transform a specific concept (e.g., “wheel”) in a consistent manner across classes. This way, if the editing process is successful, performing the edit using a few of these images should significantly improve the performance of the model on other transformed images.
To setup such scenarios in a scalable manner, we leverage a pipeline based on pre-trained instance segmentation models and style transfer (we manually collect a set of textures to use as styles).
With this pipeline in place, we evaluate editing across a wide range of examples and measure how many of the errors caused by these transformations get corrected. As a baseline, we compare ourselves to fine-tuning of either the whole network, or of all the layers after the one that we perform editing on.
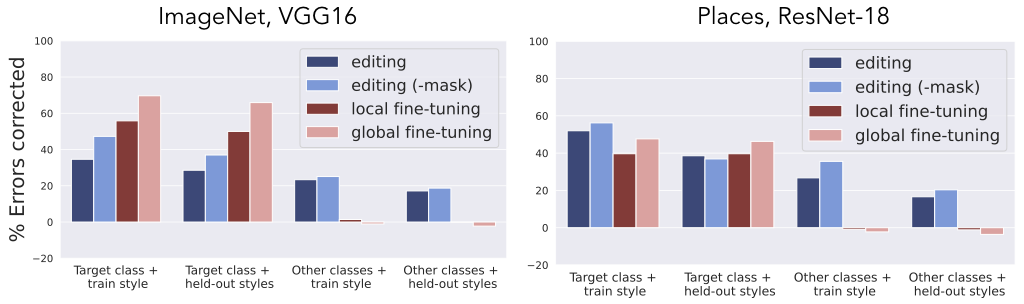
Looking at these results, we can observe that when measuring the impact of editing and fine-tuning on images of the same class used during editing, both methods perform reasonably well. However, when we focus on images of other classes—which would reflect actual generalization—editing continues to correct errors while fine-tuning often causes more errors than it fixes!
Beyond editing: Synthetic test cases as counterfactuals
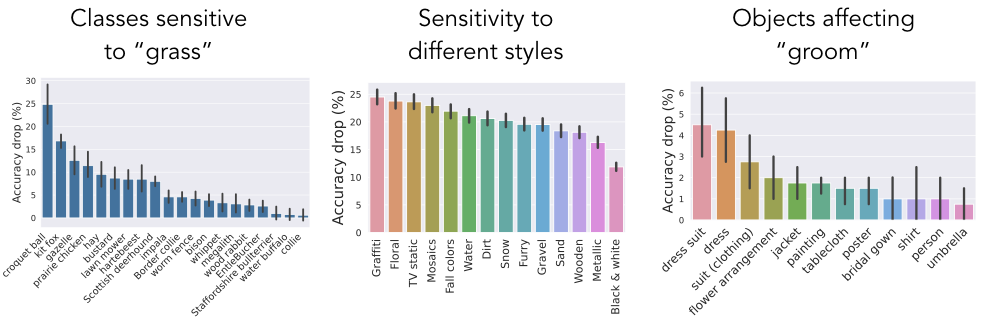
While we developed the above pipeline with the goal of benchmarking editing methods in mind, it turns out to be useful more broadly. In fact, it provides us with a scalable way to evaluate models on counterfactuals, i.e., to test how the model’s prediction changes when a given concept of interest is transformed. Such counterfactuals-based analysis can be used to get a better understanding of which concepts are important for the model to recognize each class as well as to reveal model sensitivities across classes.
Moving forward
In this post, we described a framework for directly editing classification models. We saw how such editing can be a powerful and versatile primitive for correcting model behavior with minimal data gathering and human labor. However, we are still only starting to understand what is possible through this framework. What other model edits would be useful to have? How can we “localize” our edits so that they only apply to a specific context? How do we edit multiple prediction rules at once?