Recently, we introduced Platinum Benchmarks as a step toward quantifying the reliability of large language models (LLMs). In that work, we revised older benchmarks to minimize label noise, such as ambiguous or mislabeled examples, and showed that frontier LLMs still make genuine errors on simple questions. For example, as part of that work we revised a 300-problem subset of GSM8K, a dataset of grade school math word problems, and found that all LLMs we tested made at least one genuine error. If certifying the precision of just a subset of the dataset can highlight new failures across models, what if we scale to all of GSM8K?
Today, we’re releasing GSM8K-Platinum, a revised version of the full GSM8K test set. Our comparative evaluation of several frontier LLMs on both the original and revised datasets demonstrates that GSM8K-Platinum provides a more accurate assessment of mathematical reasoning capabilities, revealing differences in performance that were previously hidden.
Why GSM8K?
GSM8K has been a cornerstone benchmark for evaluating mathematical reasoning in large language models. Indeed, the dataset remains remarkably popular––with over 350,000 downloads just last month (February 2025) on HuggingFace.
Yet, performance of frontier models on this benchmark has seemingly plateaued around 95% accuracy. Many recent frontier model releases (including o1 and Claude 3.7 Sonnet) have excluded GSM8K evaluations, opting instead to evaluate on more challenging benchmarks.
Our previous work suggested that this “plateauing” is in large part caused by label noise. So, in order to effectively differentiate state-of-the-art models, the key might not just be harder benchmarks, but also more precise (i.e., less noisy) benchmarks. By constructing GSM8K-Platinum, we can now accurately quantify how much of this perceived performance plateau was due to benchmark noise versus actual model failures.
What did we learn?
We applied our platinum benchmark methodology to revise the GSM8K test set. This involved running a variety of frontier LLMs and inspecting all questions where any LLM disagreed with the stated answer. We then manually inspected the 219 flagged questions, of which 110 were removed, 99 were verified, and 10 had mislabeled answers that were corrected. Reasons for removing questions included ambiguity (leading to multiple valid interpretations of a question) and logical inconsistencies within the problem itself. Note that we did not modify any questions beyond revising answers.
The most striking finding from our work is how revising the benchmark reveals performance differences between frontier models that were previously obscured by label noise:
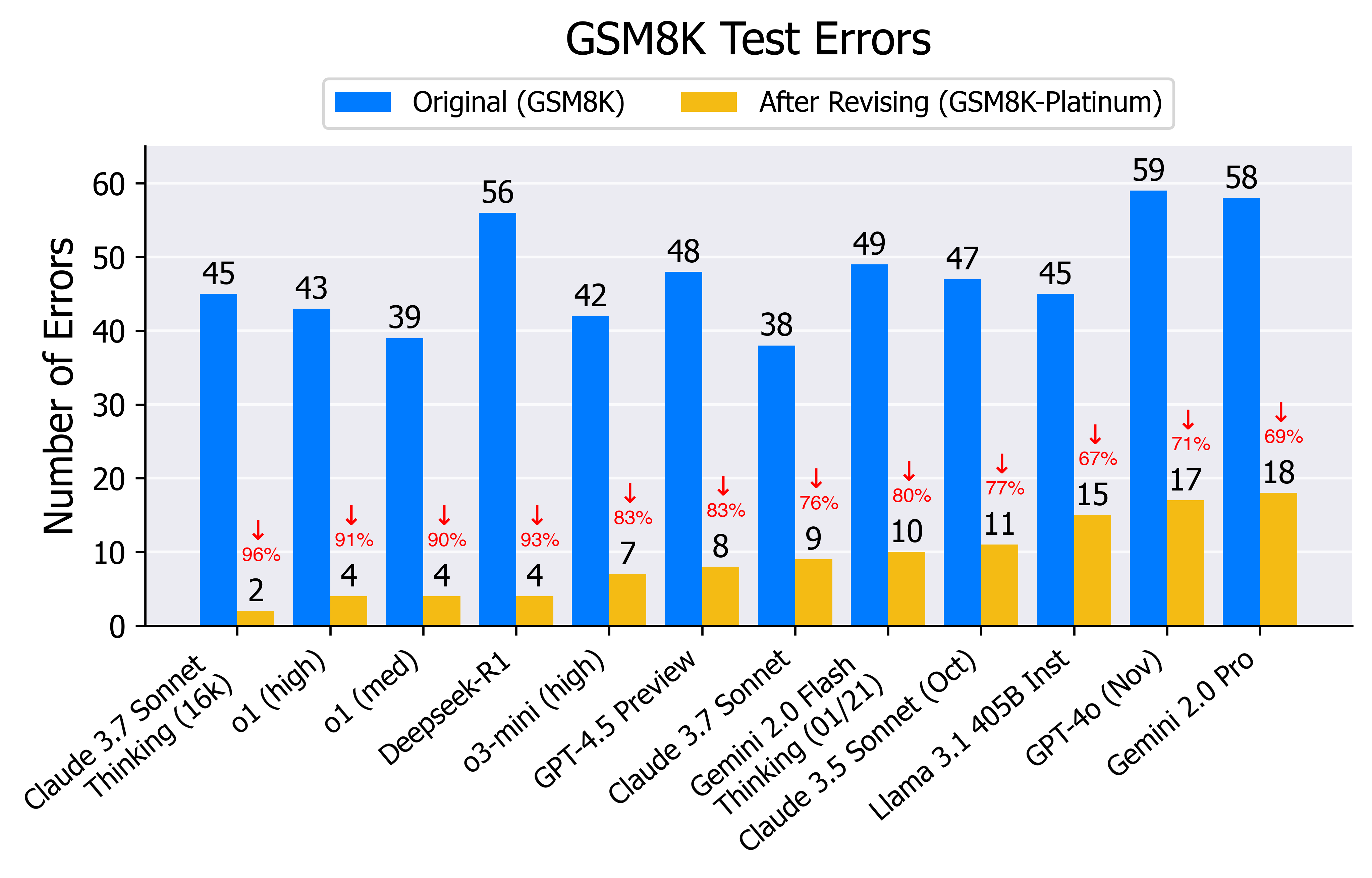
As shown above, the ranking of models on the revised GSM8K-Platinum differs significantly from that of GSM8K. Interestingly, the new ordering seems to align well with common perceptions of which models are better.
For example, both Claude 3.7 Sonnet (extended thinking) and Llama 405B showed identical error counts of 45 each on GSM8K. This seems quite strange–after all, Claude 3.7 Sonnet (extended thinking) came out almost a year after Llama 405B, was trained explicitly for better mathematical reasoning, and significantly outperforms Llama 405B on other math benchmarks like MATH. On GSM8K-Platinum, however, Claude 3.7 Sonnet (extended thinking) shows only 2 errors compared to Llama 405B’s 17 errors. Llama 405B makes 8 times as many errors, but this performance difference was obscured in the original benchmark due to noise.
Using GSM8K-Platinum
GSM8K-Platinum is now available on HuggingFace as a drop-in replacement for GSM8K. We’ve also updated our error viewer with results from frontier models evaluated on this revised benchmark.
We invite everyone to use GSM8K-Platinum for more accurate model evaluation. Additionally, we encourage the community to contribute to constructing further platinum benchmarks, such as by developing methods to more efficiently revise existing benchmarks.
For those interested in learning more about our platinum benchmarks, please refer to our previous blog post and paper.