In our previous post, we discussed the different reasons that a model might fail under distribution shift. We found that fine-tuning a pre-trained model can address certain types of failures, but not others. In this post, we illustrate how one might operationalize this understanding to develop more robust models.
Recap: what are the failure modes that pre-training can and cannot address?
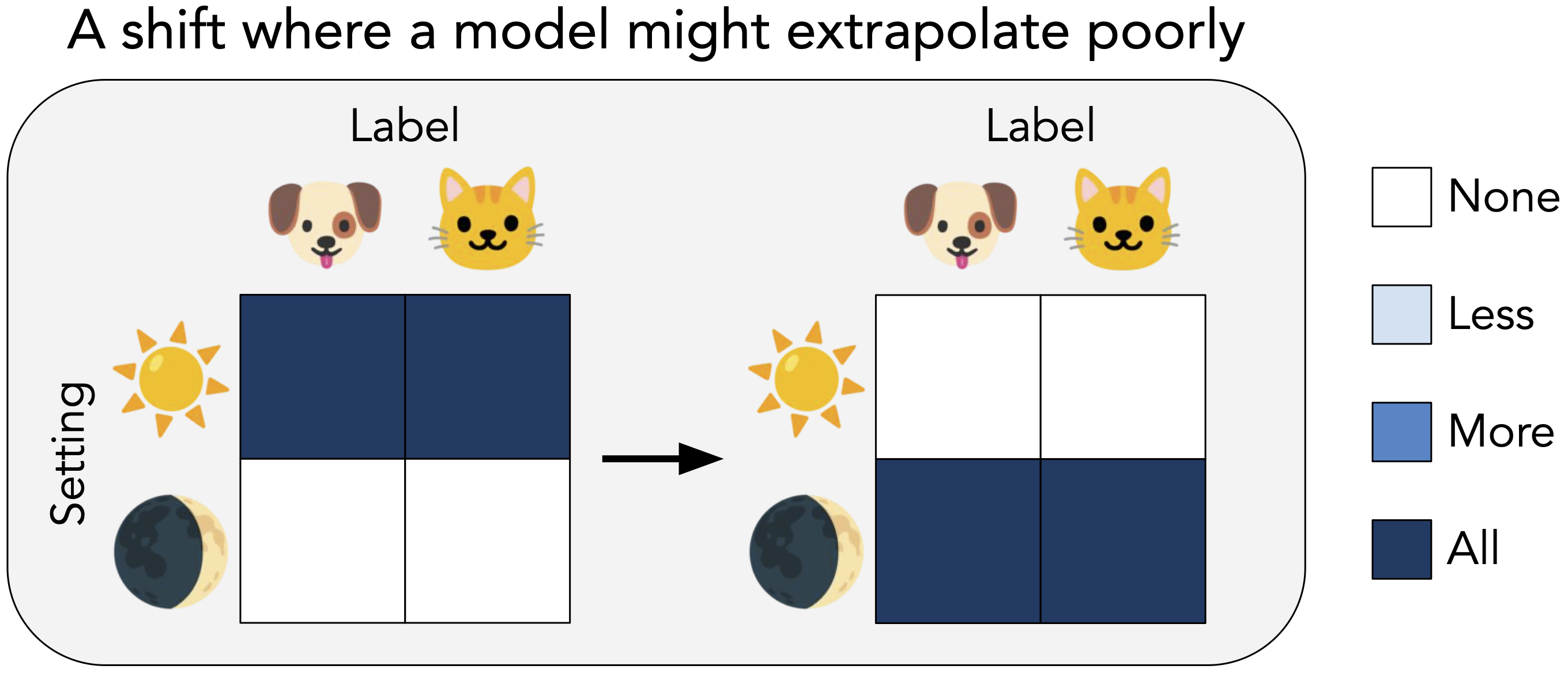
One reason that a model might fail under distribution shift is that it encounters examples that look unlike any it was exposed to during training. More concretely, a model trained to classify dogs vs. cats and trained only on photos taken during the day might struggle when presented with photos taken at night. In other words, the model may extrapolate poorly outside of the reference distribution.
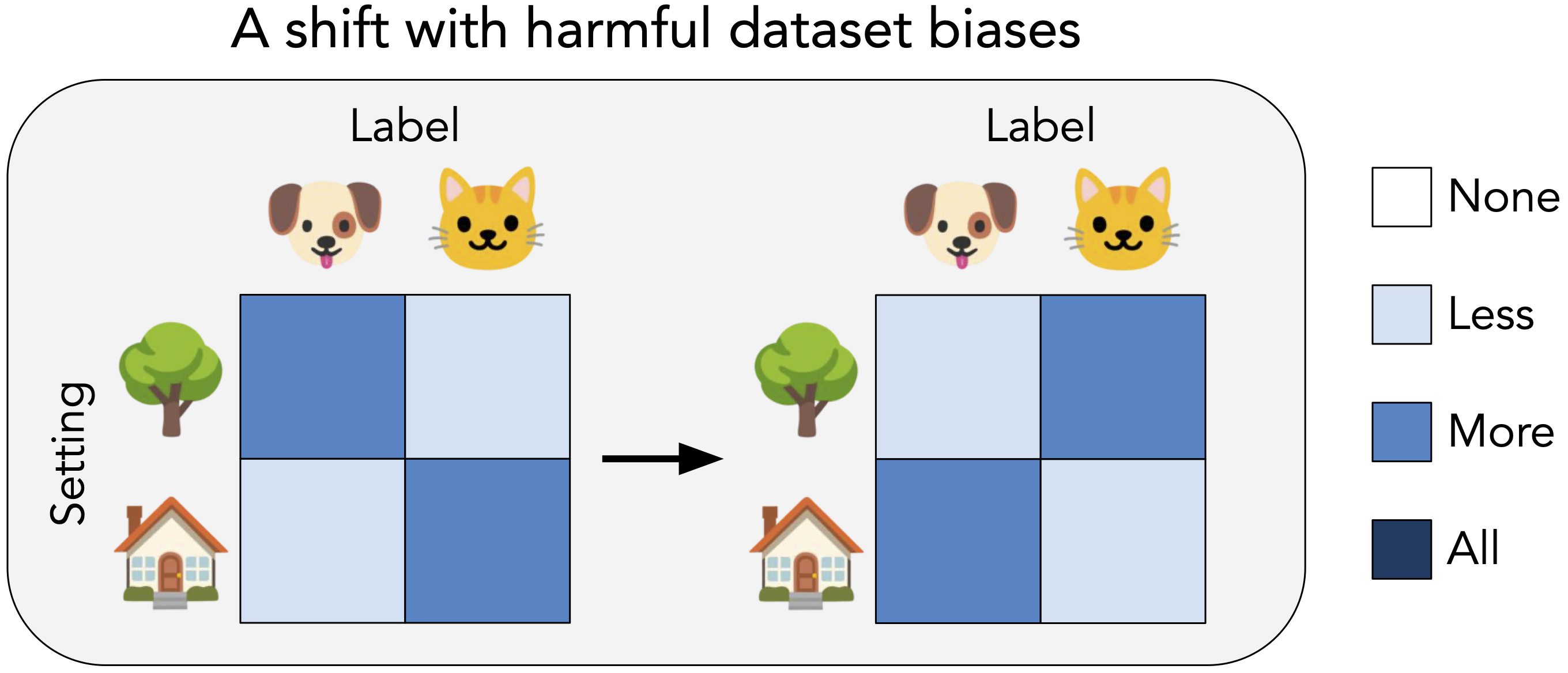
Another reason is that the model’s training dataset contains biases. Suppose that in a cat vs. dog classification setting, cats mostly appear indoors and dogs mostly appear outdoors. A model might learn to rely on the indoor vs. outdoor setting when making predictions and fail when an animal appears in an unexpected environment.
In our work, we illustrate that, as a rule of thumb, pre-training can mitigate the former failure mode, but not the latter. Intuitively, pre-training can help with extrapolation by providing features that generalize across environments. However, when they are fine-tuned, pre-trained models are just as susceptible to learning undesirable biases as models trained from scratch.
How can we harness pre-training to develop robust models?
Let’s now try to apply this rule of thumb to develop a robust hair color classification model! We’ll be working with CelebA, a dataset of celebrity faces. In this dataset, hair color is spuriously correlated with other attributes (especially gender). For example, 24% of females are blond, while only 2% of males are blond.

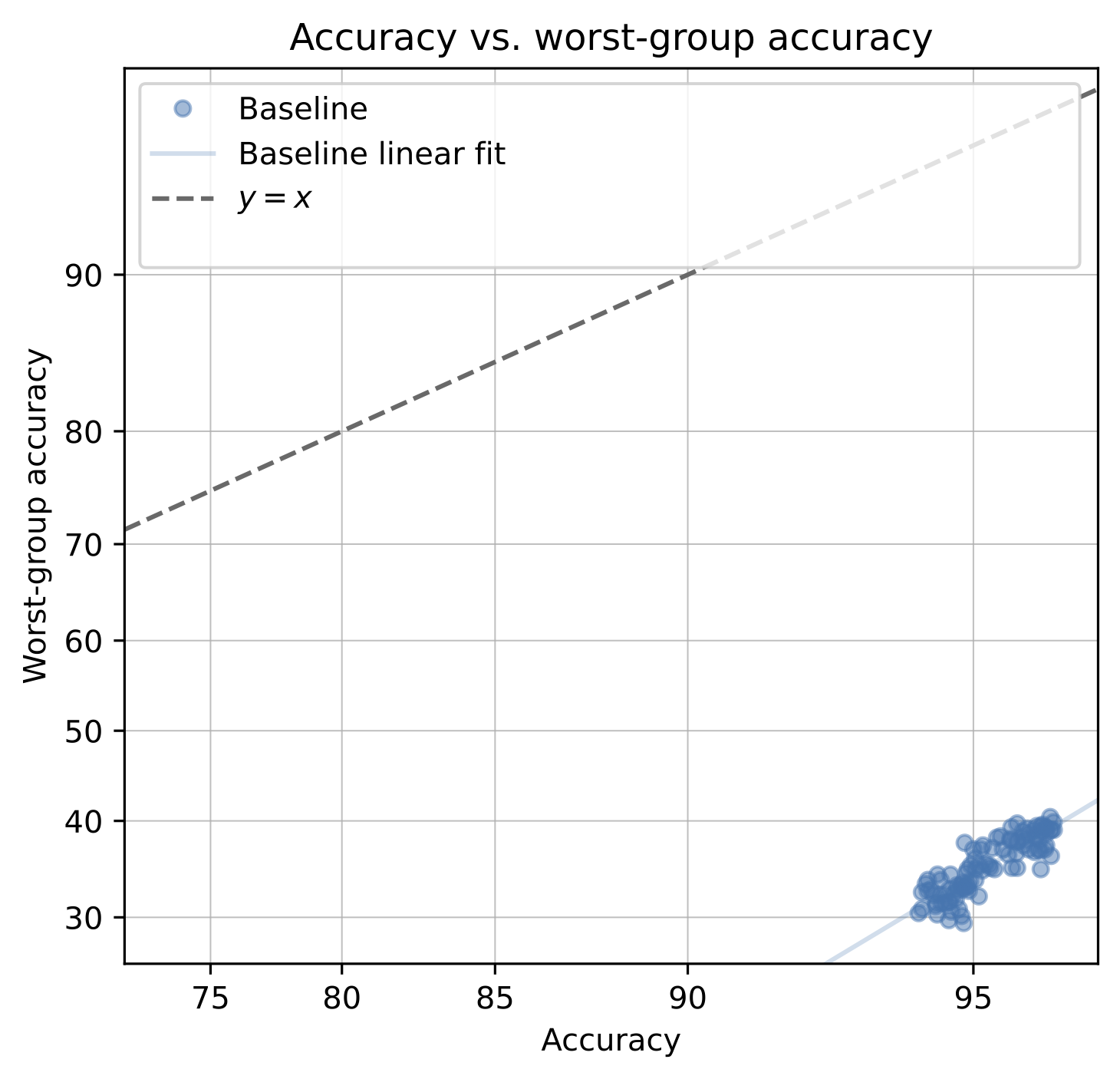
If we naively train a model on this dataset, it will be biased towards predicting females as blond and males as non-blond. When we measure the worst-group accuracy—the minimum accuracy across blond females, blond males, non-blond females and non-blond males—we find that models trained from scratch on this dataset severely underperform on certain groups.
To visualize this, we plot the worst-group accuracy of models against their standard accuracy. We’d like worst-group accuracy to be close to standard accuracy; this would mean that a model performs similarly across groups. However, the worst-group accuracies of baseline models are well below their standard accuracies.
How can we solve this problem? Let’s first try fine-tuning a pre-trained model. We’ll measure its effective robustness (ER): the increase in worst-group accuracy over the baseline of models trained from scratch. Unfortunately, pre-training does not seem to help much.
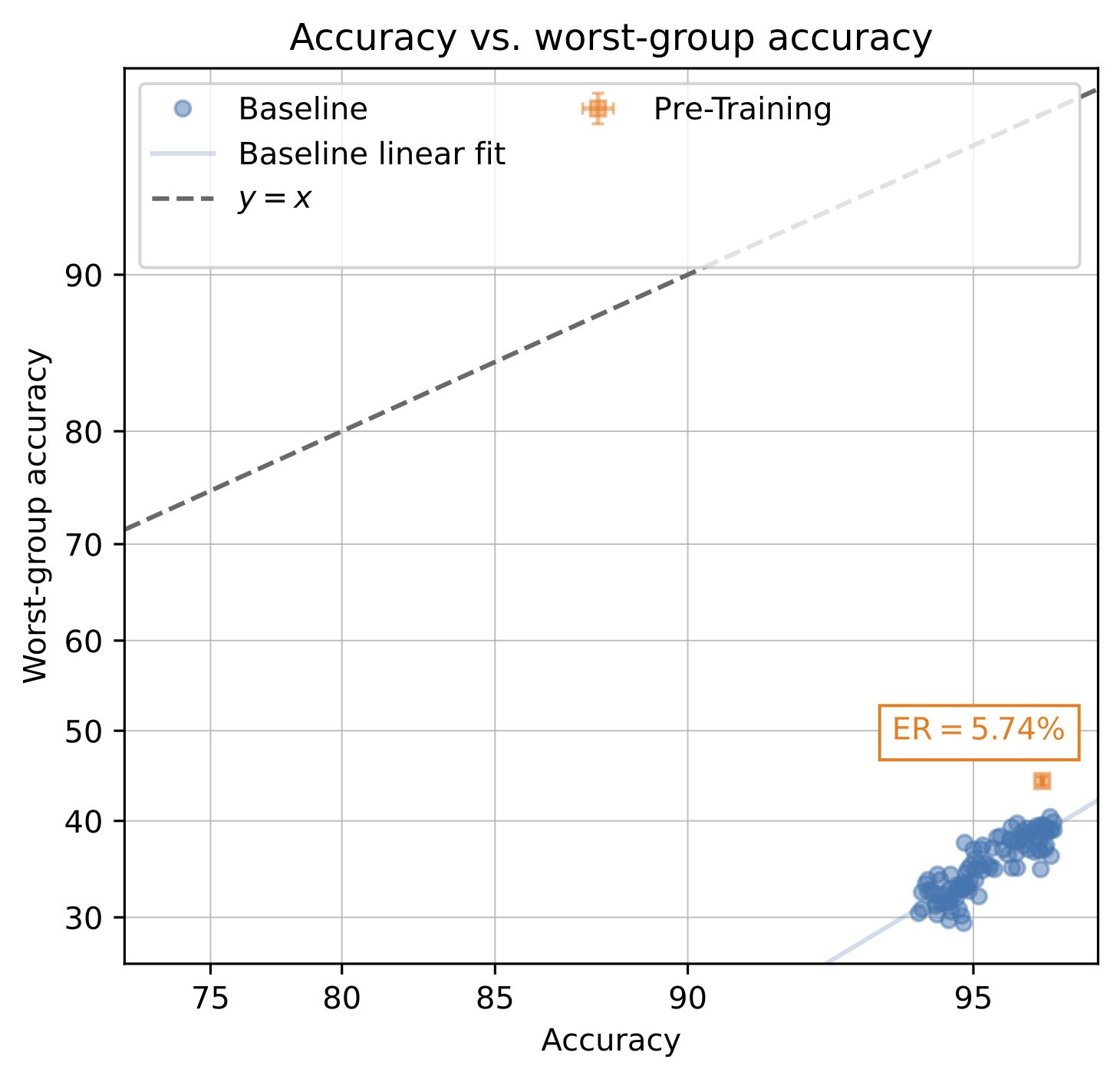
This is consistent with our previous finding that pre-training cannot address harmful biases in the reference dataset. How then can we avoid these dataset biases? One option is to curate a de-biased dataset in which hair color is uncorrelated with other attributes.
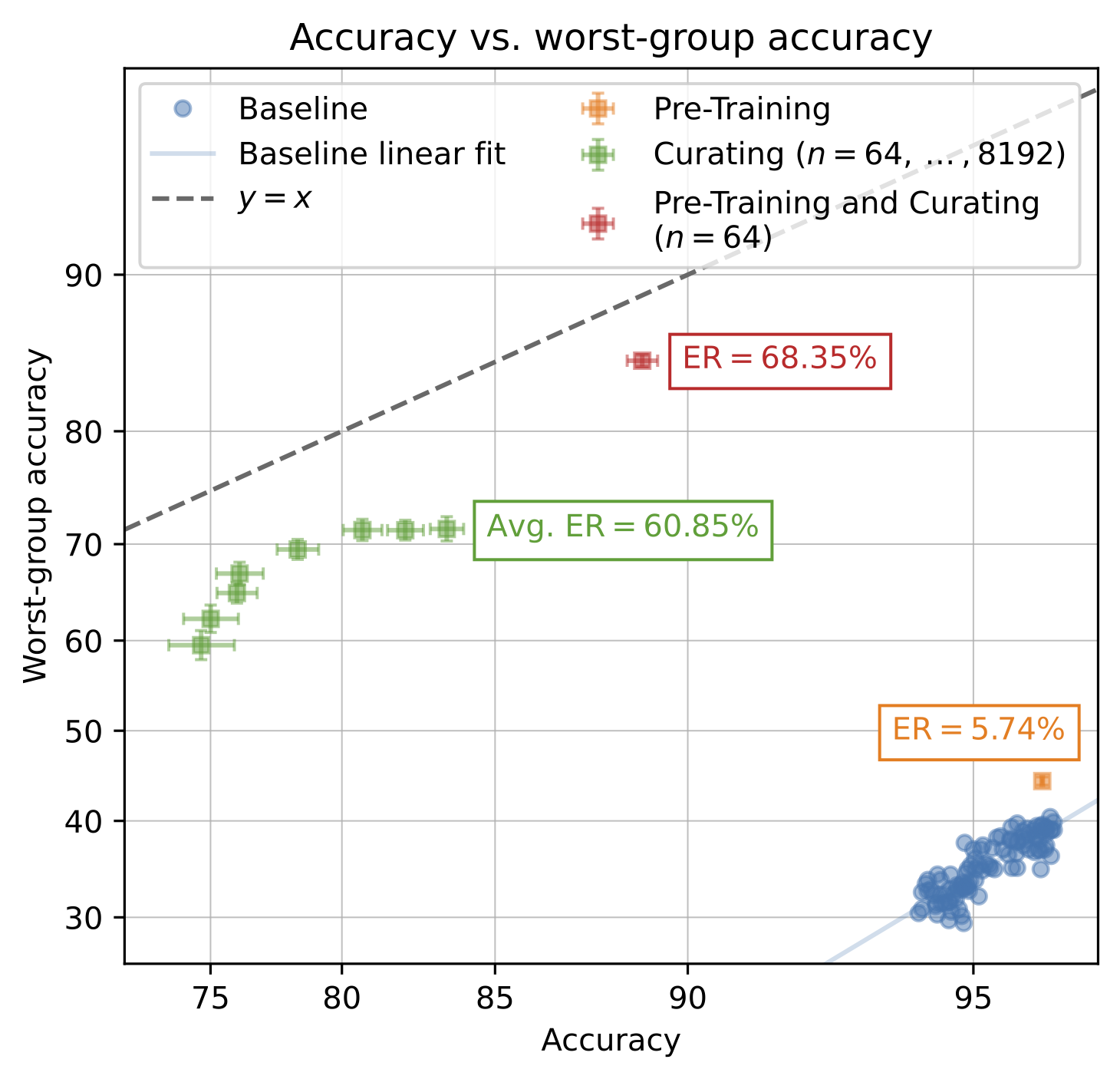
We’re now faced with another challenge: curating a large, diverse and de-biased dataset might be really difficult and/or resource-intensive. This time, though, pre-training can help! If we can rely on pre-training for extrapolation, we might only need a small, non-diverse fine-tuning dataset, which would be more feasible to de-bias. Let’s try to create such a de-biased fine-tuning dataset.
To ensure that hair color is uncorrelated with other attributes, we pair real images from CelebA with synthesized “counterfactual examples” of the opposite class. These counterfactuals depict the same individual but with a different hair color. Hence, attributes besides hair color are equally represented among the blond and non-blond populations. We restrict this dataset to just 64 examples and only females to illustrate that it does not need to be large or diverse.

When we fine-tune a pre-trained model on this curated dataset, we obtain a robust and performant model!
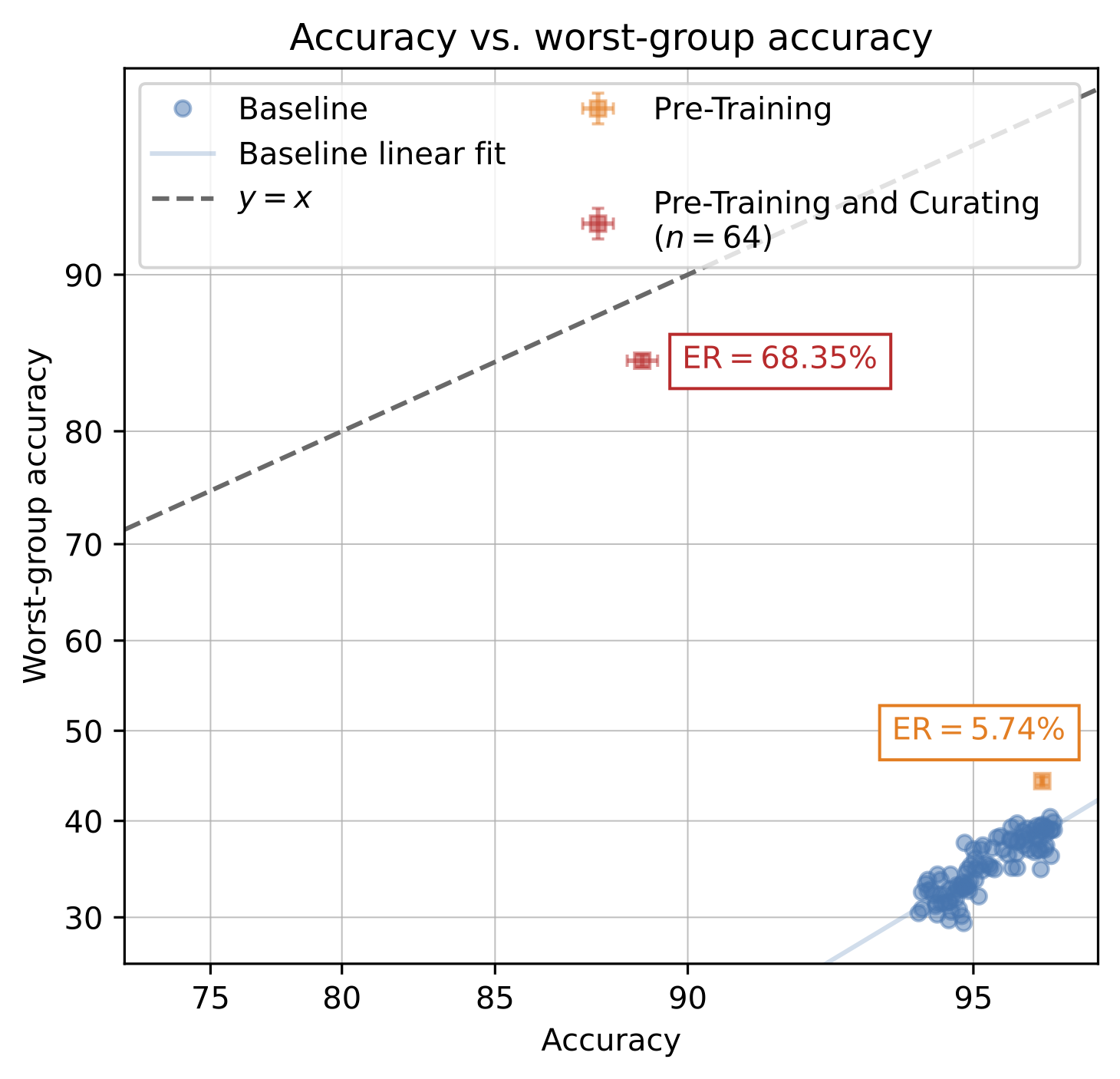
Finally, note that pre-training is crucial to make this strategy work; when we train models from scratch on our curated dataset, they are substantially less robust and performant, even with (a lot) more examples!
Conclusion
In this post, we apply our intuition about how pre-training can improve robustness to develop a robust model for hair color classification. More generally, our intuition suggests that when fine-tuning a pre-trained model, carefully curating a small, non-diverse but de-biased dataset can be an effective strategy to develop robust and performant models.