Modern computer vision systems are sensitive to transformations and corruptions of their inputs, making reliability and safety real concerns at deployment time. For example, fog or snow can severely impact self-driving cars’ perception systems; in an earlier post, we found that even changes in image background are often enough to cause model misbehavior. Techniques like data augmentation, domain randomization, and robust training can all improve robustness, but tend to perform poorly in the face of the unfamiliar distribution shifts that computer vision systems encounter in the wild.
How can we make classifiers more robust?
So far, most approaches to robust machine learning have focussed on better model
training methods. However, there is more than one way to peel a banana. Instead
of tackling the general problem of designing universally robust vision
algorithms, we leverage an additional degree of freedom present in many
real-world scenarios. Specifically, we observe that in many situations, the
system designer not only trains the model used to make predictions, but also has
the ability to modify objects of interest. Critically, such a system designer could
modify objects to improve the model’s performance! For example, a drone
operator training a landing pad detection model can modify the landing pad
surface for easier detection, and a roboticist manipulating custom objects could
alter objects’ texture or geometry to assist with perception. Indeed, a similar
insight motivates QR codes, which are patterns explicitly designed to encode
easily recoverable bits in photographs. In our work, we ask: can we reliably
create objects that
Designing objects for robust vision
Research on adversarial examples has demonstrated that modern vision models can be extraordinarily sensitive to small changes in input: carefully chosen yet imperceptible perturbations of natural images can cause models to make wildly inaccurate predictions. In particular, previous work has shown that we can perturb objects’ textures so that they induce misclassification when photographed [Kurakin et al.]. Indeed, Athalye et al. 3D print a textured turtle that looks like a turtle, but classifies as a rifle when shown to a classifier!
So, given that we can make objects fool ML models, can we also make them help?
The answer is yes! In our work, we turn the same oversensitivity behind adversarial examples into a tool for robustly solving vision tasks. Specifically, instead of optimizing inputs to mislead models (as in adversarial attacks), we optimize inputs to reinforce correct behavior, yielding what we refer to as unadversarial examples or robust objects.
We demonstrate that even a simple gradient-based algorithm can successfully construct unadversarial examples for a variety of vision settings. In fact, by optimizing objects for vision systems (rather than only vice-versa) we can greatly improve performance on both in-distribution data and previously unseen out-of-distribution data. For example, as illustrated below, optimizing the texture of a 3D-modelled jet enables the image classifier to classify that jet more robustly under various weather conditions, despite never being exposed to such conditions in training:

The model correctly classifies both the original jet and its unadversarial counterpart in standard conditions, but recognizes only the unadversarial jet in foggy and dusty conditions.
Constructing unadversarial examples
Our paper proposes two ways of designing robust objects: unadversarial stickers (patches), and unadversarial textures:

As with adversarial examples, we construct both unadversarial patches and textures via gradient descent. In both cases, we need a pre-trained vision model to optimize objects for:
- Unadversarial patches: To construct/train unadversarial patches, we repeatedly sample natural images from a given dataset, and place a patch onto the sampled image (with random orientation and position) corresponding to the label of the image. We then feed the augmented image into the pre-trained vision model, and use gradient descent to minimize the standard classification loss of the model with respect to the patch pixels. The procedure is almost identical to that of Brown et al. for constructing adversarial patches; the main difference is that here we minimize, rather than maximize, the loss of the pre-trained model.
- Unadversarial textures: To construct adversarial textures, we start with a 3D mesh of the object we would like to optimize, as well as a dataset of background images. At each iteration, we render the current unadversarial texture onto the 3D mesh, and overlay the rendering onto a random background image. The result is fed to the pre-trained classifier, and we (again) use gradient descent to minimize the classification loss with respect to the texture. In previous work, Athalye et al. use an extremely similar approach to optimize adversarial textures (the most famous example of which being the rifle turtle).
Evaluating unadversarial examples
After designing our unadversarial examples, we evaluate them in two ways. First, we want to ensure that classifiers still maintain (or improve on) high accuracy levels on standard benchmarks augmented with unadversarial examples. Second, we want to understand the extent to which patches confer robustness to out-of-distribution samples—how well do models perform on patches under distribution shifts, despite such shifts never being considered in training?
To answer these questions, we first test our methods on standard datasets (ImageNet and CIFAR) and robustness benchmarks (CIFAR10-C, ImageNet-C). It turns out that adding unadversarial patches to ImageNet dataset boosts the ImageNet accuracy as well as the robustness of a pretrained ResNet-18 model under various corruptions!
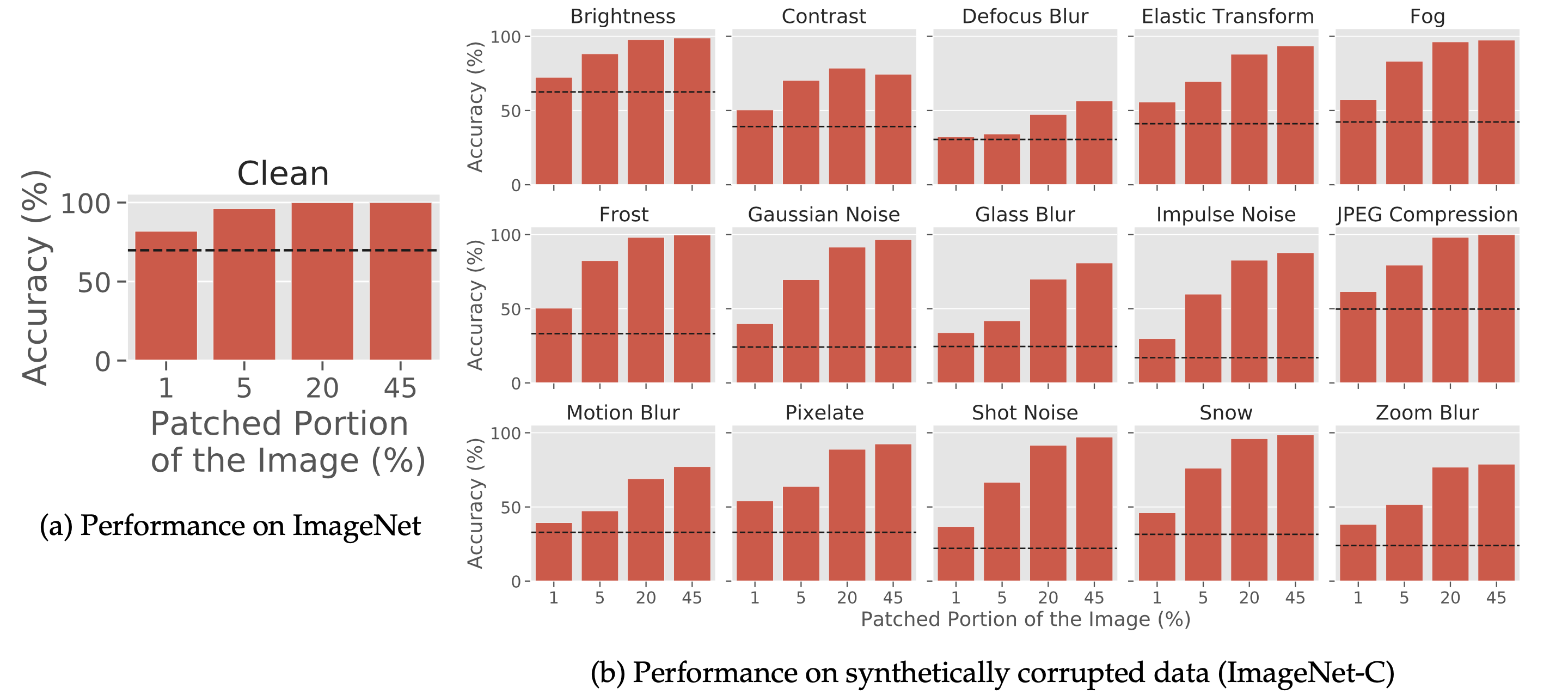
In our paper, we also compare to some non-optimization based baselines, like QR code-based augmentation and predetermined patches; unadversarial patches comfortably outperform all of the baselines we tested.
How do robust objects fare in more realistic settings?
The promising results we observe on standard classification and synthetic corruption benchmarks motivate us to consider more realistic tasks. To this end, we extend our evaluation to consider unadversarial examples in three additional settings: (a) classifying objects in a high-fidelity renderer, (b) localizing objects in a drone-landing simulator, and (c) recognizing objects in the real world. In the first two (simulated) settings, we optimize over objects’ textures directly and simulate weather conditions in the renderings themselves. In the final setting, we print out patches designed for ImageNet and study how well they aid classification when photographed on real world objects.
A) Recognizing Objects in a High-Fidelity Simulator
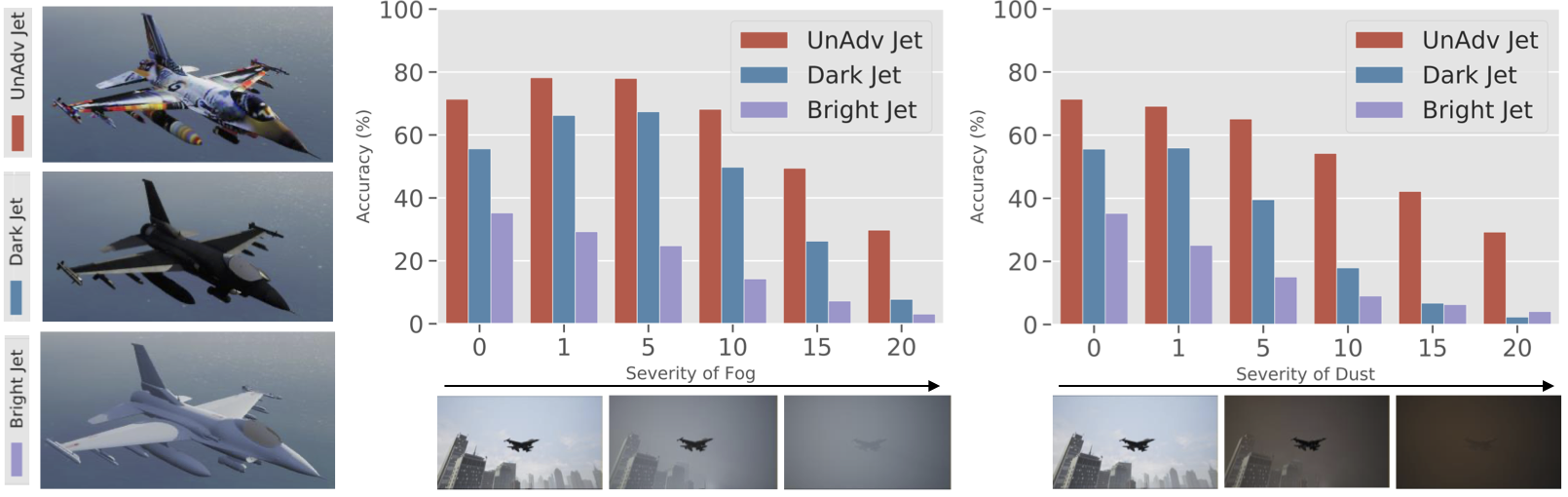
We first test how well unadversarial examples aid recognition of three-dimensional objects in a high-fidelity simulator. Generating unadversarial textures for objects corresponding to ImageNet classes, such as “warplane” and “automobile,” we then use Microsoft AirSim to evaluate how well the unadversarial textures help classification in both standard and severe weather conditions—like fog and snow (note that in AirSim these weather conditions are explicitly simulated in the 3D scene, and not applied through image post-processing). We observe that our unadversarial models are much more recognizable than their original counterparts by the pre-trained ImageNet model, especially under distribution shift. For example, our unadversarial jet beats the baselines “Bright Jet” and “Dark Jet,” textures manually designed with the goal of visibility in severe weather) in a variety of weather conditions and severities:
B) Localization for (Simulated) Drone Landing
We then take the realism of our simulations a step further by training unadversarial patches for a simulated drone landing task. The drone is equipped with a pre-trained regression model that localizes the landing pad. To improve localization, we place an unadversarial patch on the pad and optimize it by minimizing a squared error loss (instead of a classification loss as in the previous experiments) corresponding to the drone’s error in predicting landing pad location. We then evaluate the effectiveness of the patch by examining the landing success rate in clear, moderate, and severe (simulated) weather conditions. As shown below, we find that the unadversarial landing pad improves landing success rate across all conditions:

C) Physical World Unadversarial Examples
Finally, we study unadversarial examples’ generalization to the physical world. Printing out unadversarial patches, we place them on top of real-world objects and classify these object-patch pairs along a diverse set of viewpoints and object orientations. Our results are detailed below; we find that the unadversarial patches consistently improve performance despite printing artifacts, lighting conditions, partial visibility, and other naturally-arising distribution shifts.

Conclusions
We have shown that it is possible to design objects that improve the performance of computer vision models, even under strong and unforeseen corruptions and distribution shifts. By minimizing the standard loss of a pre-trained model, without training for robustness to anything specific, we significantly boosted both model performance and model robustness across a variety of tasks and settings. Our results suggest that designing unadversarial inputs could be a promising route towards increasing reliability and out-of-distribution robustness of computer vision models.