Paper
Code
In our latest paper, we present a framework for pinpointing the impact of the source datasets in transfer learning. Our framework enables us to improve transfer learning performance by removing source datapoints that are detrimental for a specific target task. It also unlocks various other capabilities, such as debugging transfer learning failures, automatically identifying granular subpopulations in the target dataset, and detecting data leakage between source and target datasets.
Transfer learning is a widely utilized technique for adapting a model trained on a source dataset to improve performance on a downstream target task. Used in applications ranging from radiology, autonomous driving, to satellite imagery analysis, the transfer learning paradigm also fuels the recent emergence of large vision and language models trained on enormous amounts of data, such as CLIP or GPT-3.
Why is transfer learning so effective though? And, in particular, what drives transfer learning performance? Definitely, much depends on the properties of the source model, i.e., the model trained on the source dataset. For example, recent works highlight the impact of the model’s architecture, accuracy, adversarial vulnerability, and training procedure.
But, in addition to the source model, it is hard to not expect the source dataset to play a major role as well. Indeed, several works have shown that increasing the size of the dataset usually boosts transfer learning performance. Others have found that limiting the source dataset to images that are relevant to the target task can help as well. So: what is the exact role of the source dataset in transfer learning?
In our most recent paper, we present a framework for pinpointing the impact of the source dataset on the downstream predictions in transfer learning. This framework draws inspiration from techniques such as influence functions and datamodels and it enables us, in particular, to automatically identify source datapoints that—positively or negatively—impact transfer learning performance.
We’ll now walk through how we calculate the influence of the source dataset in transfer learning, and then demonstrate how our framework can be used to:
- Boost transfer learning performance by removing detrimental source datapoints;
- Automatically extract granular subpopulations in the target dataset by projecting the class hierarchy of the source dataset onto it; and
- Surface pathologies such as source-target data leakage and misleading or mislabelled source datapoints.
Computing the Influence of the Source Dataset
How to pinpoint the relationship between the source dataset’s composition and the model’s downstream predictions? We build here on the influence functions and datamodels methodology (check out our previous post for a deeper dive into these) to study the counterfactual effect of removing source datapoints on the target model’s predictions. However, unlike in the standard supervised setting in which the focus is on individual datapoints, here we focus on removing entire classes. This is motivated by the fact that we expect the removal of entire classes to have a more measurable impact on the features learned by the source model (and thus the resulting model’s predictions).
So, at a high level, we first train a large number of models on random subsets of classes in the source dataset, and fine-tune them on the target task. Then we compute the influence of a source class on a target example by simply measuring the average difference in the model’s performance on a given target example when the class was included versus excluded from the source dataset. A positive influence value thus means that including the class improved the model’s performance on that example, while a negative value indicates that the class was detrimental to the correctness of the corresponding model’s prediction.
Identifying the Most Influential Classes of the Source Dataset
Now that we’ve calculated these influences, how can we use them to study transfer learning? First, let’s take a look at the ranking of the most positively and negatively influencing classes for a variety of target tasks. We first look at the influences from different ImageNet classes to the entire CIFAR-10 test set:
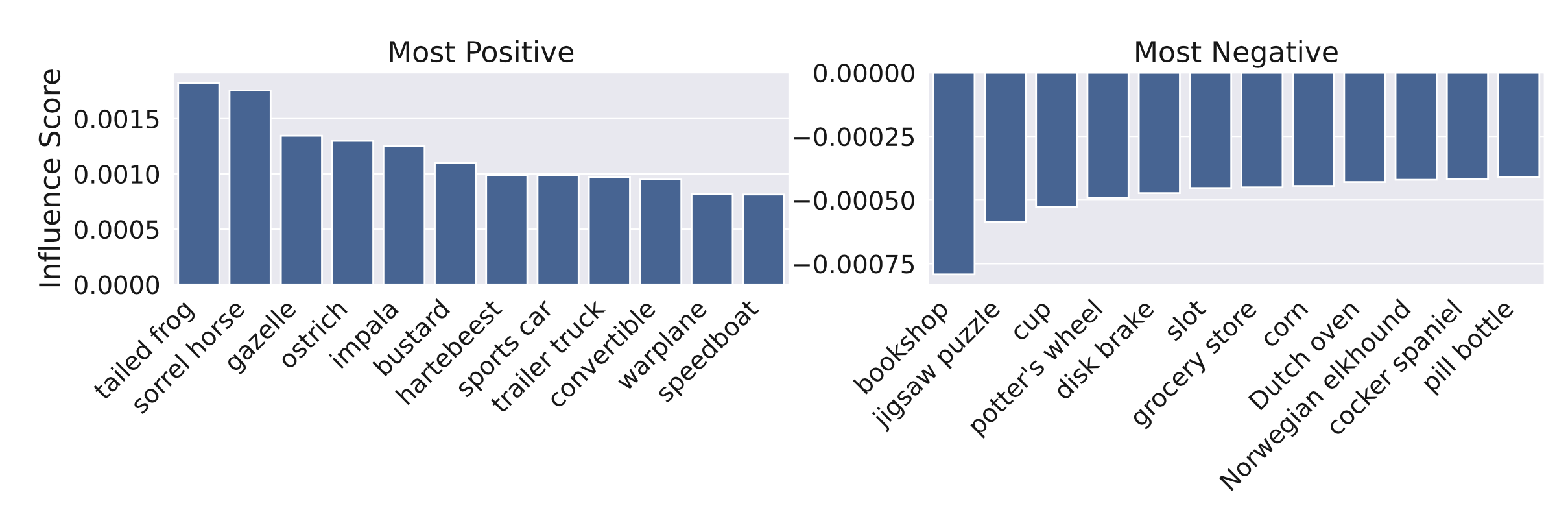
Note that in the most positive source classes tend to semantically overlap with the classes in the target dataset. For example, tailed frog and sorrel horse have the most positive influence for the CIFAR-10 dataset, which contains the classes frog and horse.
Also, the plot above suggests that there is a number of source classes, such as bookshop or jigsaw puzzle, whose inclusion actually hurts the overall transfer learning performance. So what happens if we indeed remove these classes from the source dataset? Well, as one might hope, they do boost the transfer learning performance on a variety of downstream image classification:
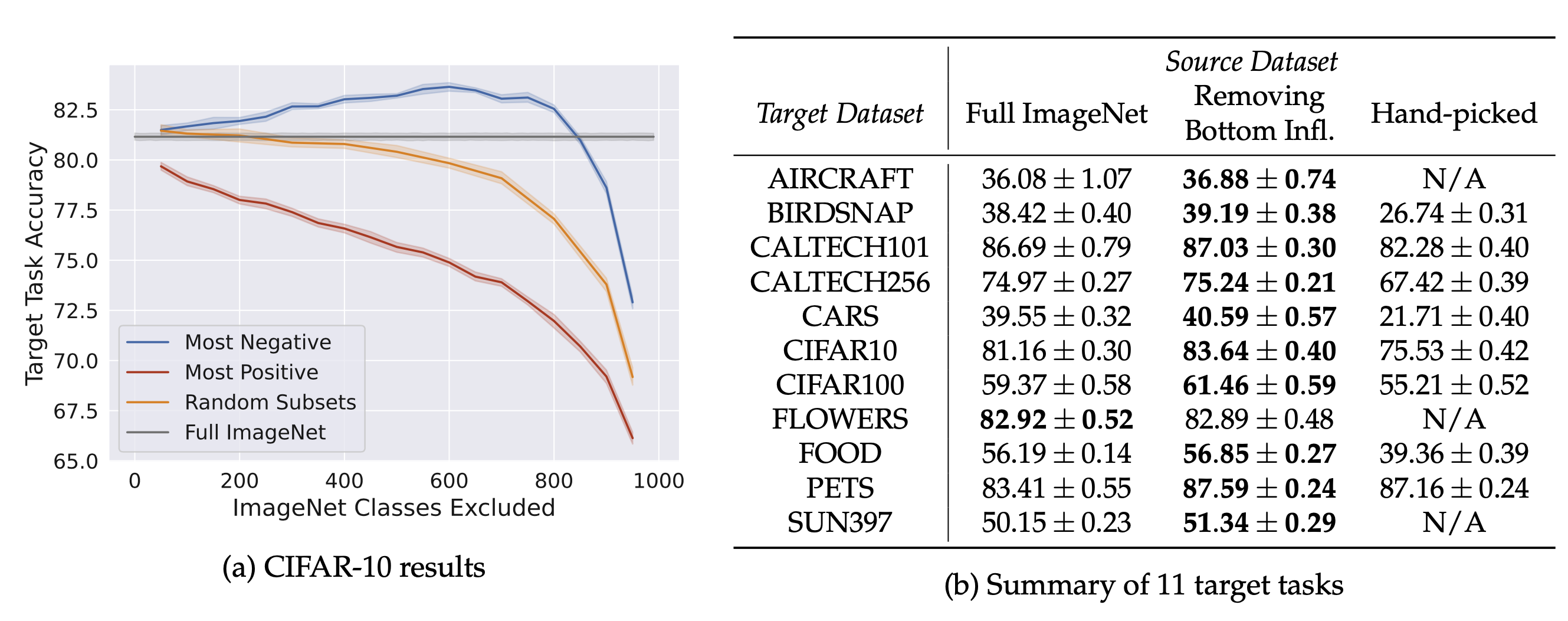
In fact, we can get an accuracy boost of nearly 2.5% on CIFAR-10 (as compared to what one gets from pre-training with the full ImageNet dataset).
Leveraging Influences to Study Transfer Learning
Above, we used our framework to pinpoint the most influential—be it positively or negatively— classes for transfer learning. Here, we’ll discuss how our framework provides us with a broader set of tools for studying transfer learning, including: (1) debugging transfer learning failures, (2) automatically extracting granular subpopulations in the target dataset, and (3) detecting data leakage between source and target datasets.
(1) Debugging the failures of the transferred model
Suppose our transferred model wrongly predicts the dog image displayed in the figure below—it labels it as a horse. Can we use our framework to understand why our model is making this mistake? Yes! The influences we computed enable us to identify the source class sorrel horse as one having a strong (and the strongest) negative influence on our image of interest. This suggests that the features learned by the source model due to the presence of this class might be the culprit here. Indeed, once we remove the sorrel horse class from the source dataset, our model now makes the correct prediction on our dog image much more frequently (with respect to the randomness of the training procedure).
(2) Automatically extracting granular subpopulations in the target dataset
Imagine you want to find all the images of ostriches in the CIFAR-10 dataset. However, the problem is that CIFAR-10 does not contain any subpopulation annotations that could help with this task and having to manually look for ostriches among all the images in the bird class is not a very appealing alternative. Our framework allows us to do something much more scalable!
Indeed, as we already observed, the most positively influencing source classes usually semantically overlap with the images in the target dataset they influence the most. In fact, this goes further: the target images which are most influenced by a given source class tend to share relevant salient features too. So, to identify our ostrich subpopulation in CIFAR-10, we just need to look at all the images that are most influenced by the source class “ostrich”! Below we display some of the CIFAR-10 images identified in this way.
(3) Detecting data-leakage and misleading source dataset examples
Thus far, we have focused on the role of classes in the source dataset in transfer learning. But we can also compute the influences of specific source examples on the transferred model’s predictions. This turns out to enable us to isolate, in particular, instances of data leakage and misleading examples in the source dataset.
Indeed, below, we display ImageNet training examples that are highly influential on CIFAR-10 test examples. The source images that have a highly positive influence are often identical copies of images from the target task (just at a higher resolution)—a clear example of data leakage. On the other hand, images that have a high negative influence tend to be the ones that are misleading, mislabeled, or otherwise surprising. For example, the presence of the (amusing) ImageNet image of a flying lawnmower (see below) hurts the performance on a CIFAR-10 image of a regular (but similarly shaped) airplane.

Conclusions
In this post, we described a new framework for pinpointing the impact of the source dataset in transfer learning. Our framework allows one to improve the transfer learning performance on a range of downstream tasks by identifying and removing source datapoints that are detrimental. Furthermore, by using our framework one can automatically extract granular subpopulations in the target dataset by leveraging the fine-grained class hierarchy of the source dataset, better understand how the errors of the model on the downstream task are rooted in the source dataset, and detect potential data leakage from the source to the downstream dataset. We believe our framework provides a new perspective on transfer learning by highlighting the role of the source dataset in the transfer learning pipeline and gives us a toolkit for performing a fine-grained analysis of it.