In our previous blogpost we described a method for automatically distilling a model’s failure modes as directions in a latent space. In this post, we’ll discuss how we can combine this method with off-the-shelf text-to-image models to perform synthetic data augmentation that specifically targets (and thus helps mitigate) a model’s classification failures.
Machine learning models are prone to failures —especially on subpopulations which are ambiguous, corrupted, or underrepresented in the training data. For example, a CIFAR-10 classification model might fail to identify cats on grass if its training dataset contained mostly examples of cats indoors.

Our previous blog post described a method for automatically distilling such meaningful error patterns as directions in a latent space. In the context of our example above, this would correspond to identifying an axis such that the easy examples (e.g., cats inside) lie in one of its directions, and the hard ones (e.g., cats on grass) lie in the opposite direction.

However, coming up with such a consistent “hardness rating” is only half the battle. That is, once we’ve identified relevant failure modes, how can we improve the underlying model’s reliability on them? One approach (as we discuss in the paper) is to simply add more data that belongs to the corresponding subpopulations (e.g., add more examples of cats on grass). For example, we can use our method to filter examples from an external pool of data (if we do not wish to use the entire external pool due to e.g., computational constraints) that would be useful to add to the training dataset (see Figure 6 in our paper).
But what if we don’t have access to such an external pool of data? It turns out that we can directly generate the images we need! Specifically, as we show in the (revised) version of our paper, we can leverage the recent stunning progress in text-to-image generation, as exemplified by diffusion models such as Stable Diffusion, Imagen, and DALL-E 2. That is, by combining our method with off-the-shelf diffusion models, we can perform “synthetic data augmentation” to specifically target a model’s failure modes.
Recap: Identifying and Captioning Model Failure Modes
Our previous blogpost and corresponding paper presented a method for automatically identifying and captioning failure modes in a dataset. The key idea here was that, when exposed to a challenging subpopulation, the errors that a model makes are consistent, and share common features. (In our running example of cats, the hard examples tend to have outdoor backgrounds.) We can thus leverage that consistency and feature sharing by training a simple linear classifier to predict whether the original model is likely to make a mistake. Specifically, by training a linear SVM (per-class) to separate the incorrect and correct examples given their (normalized) feature embeddings.
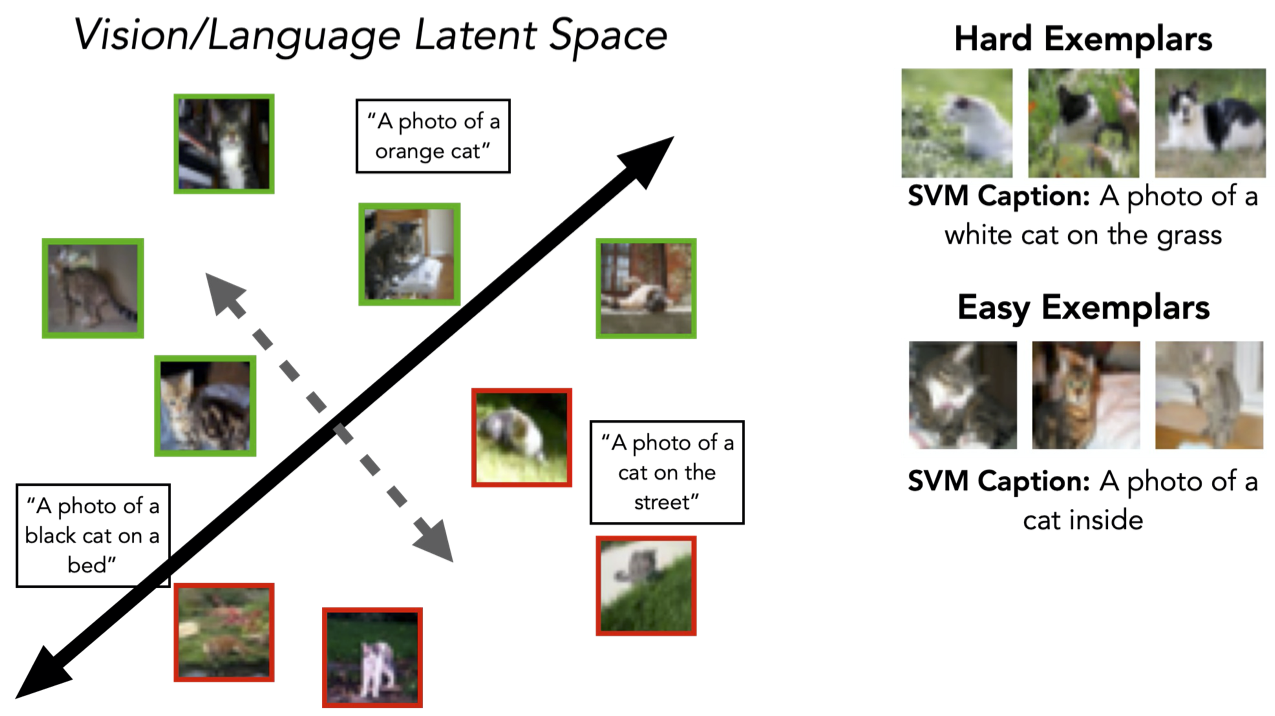
In our running example of a cat, the SVM (the black line above) learns to separate cats indoors from cats outside. The vector orthogonal to the SVM’s decision boundary (in gray) thus encapsulates the direction of the captured failure mode: the images that are most aligned (or anti-aligned) with this direction represent the most prototypically “hard” or “easy” examples.
Moreover, by leveraging a joint vision/language space for our underlying featurization (e.g., CLIP) our method provides a convenient way to caption the underlying failure modes with natural language descriptions. That is, since CLIP embeds both images and text in the same space, we can surface sentences whose text embedding is most aligned with our captured direction. In our example of cats from CIFAR-10, this method extracts “a photo of a white cat on the grass” as a hard subpopulation and “a photo of a cat inside” as an easy one.
Targeted Data Augmentation with Stable Diffusion
How can we use text-to-image diffusion models, such as Stable Diffusion or DALL-E 2, to generate synthetic images on which to fine-tune our model (thus “hardening” it against the corresponding distribution shift)? One straightforward approach is to simply use the name of the class to generate new images. For example, we can generate new examples of cats for CIFAR-10 by plugging in the sentence “a photo of a cat.”
However, just inputting “a photo of a cat” as a caption results in fairly generic examples of cats. But we wanted to perform targeted data augmentation, in order to improve the model’s reliability on our particular identified challenging subpopulations (e.g., cats on grass). Conveniently, we already discussed how to automatically surface natural language captions for the extracted failure modes. So, we can just plug these captions into our text-to-image model! Below are examples of such generated images.
How well does fine-tuning on such synthetic images fare? As one might hope, fine-tuning the original model’s final layer indeed improves model performance on the hard subpopulation (see below).
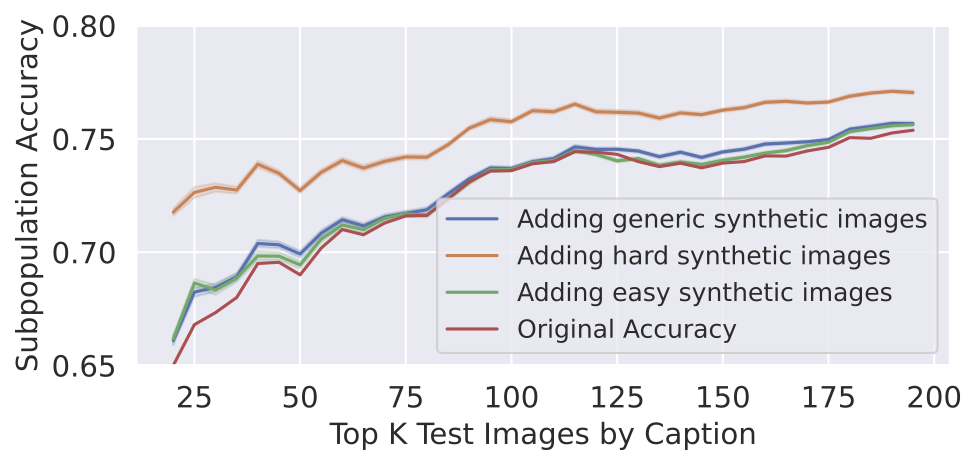
Directly synthesizing hard examples
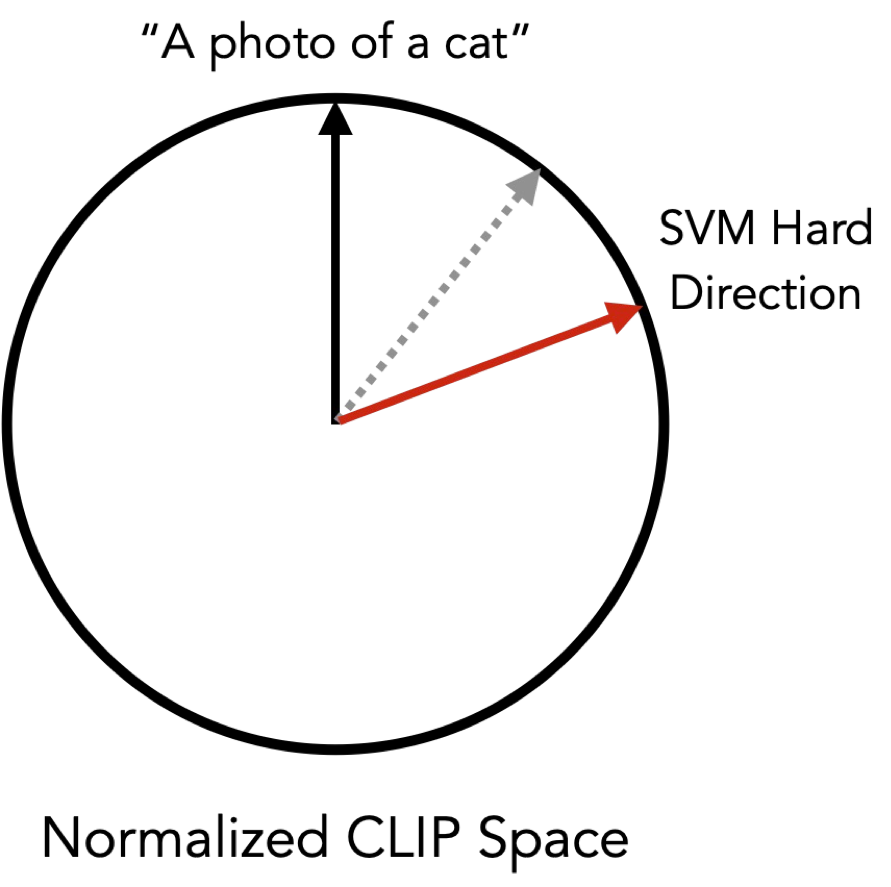
However, the above approach, although successful, feels somewhat suboptimal. After all, our initial SVM “hard” direction already lives in a joint vision/language space—and so does the Stable Diffusion model we use. Can we thus skip the intermediate captioning step and directly decode our extracted SVM direction into synthetic images?

Yes, we can! We just need to interpolate between a reference class caption (e.g., “a photo of a cat”) and our extracted SVM direction to generate either harder or easier images that correspond to our captured failure mode.
Below, we display some examples of hard (and easy) images generated for each CIFAR-10 class. Notice that the encoded directions include rich information such as background, pose, and distance to the object, which would not be conveyed by the captions alone. As our revised paper shows, the original model performs worst on the “hard” images and best on the “easy” ones.
So, indeed, by directly decoding the extracted SVM direction, we can capture the failure mode itself as a collection of new (synthetic) images, without relying on the proxy of captions!
Conclusion
In this blog post, we demonstrated how to use off-the-shelf diffusion models to perform targeted “data augmentation”, improving test accuracy on hard subpopulations to which a model might be vulnerable. This put forward a fully automated pipeline for identifying, interpreting, and intervening on challenging subpopulations. We believe that as the power of text-to-image models increases, such targeted “data augmentation” will become an even more powerful and versatile tool for improving model reliability.