We discuss our latest paper on computer vision applications of robust classifiers. We are able to leverage the features learned by a single classifier to develop a rich toolkit for diverse computer vision applications. Our results suggest the robust classification framework as a viable alternative to more complex or task-specific approaches.
In our previous post, we saw how robust models capture high-level, human-aligned features that can be directly manipulated through gradient descent. In this post, we demonstrate how to leverage these robust models to perform a wide range of computer vision tasks. In fact, we perform all these tasks by simply optimizing the predicted class scores of a single robustly trained classifier (per dataset). The resulting toolkit is simple, versatile and reliable—to highlight its consistency, in this post we visualize the performance of our method using random (not cherry-picked) samples.
Our corresponding paper can be found here, and you can reproduce all of our results using open-source IPython notebooks here. We also have a live demo where you play with a trained robust model like this:
Robust Models as a Tool for Input Manipulation
The key primitive of our approach is class maximization: maximization of class log-probabilities (scores) from an adversarially robust model using gradient descent in input space.
As discussed in our last post, robust models learn representations that are more aligned with human perception. As it turns out, performing class maximization on these models actually introduces class-relevant characteristics in the corresponding input (after all, these class log-probabilities are just linear combinations of learned representations). To visualize this, here is the result of class maximization for a few random inputs:
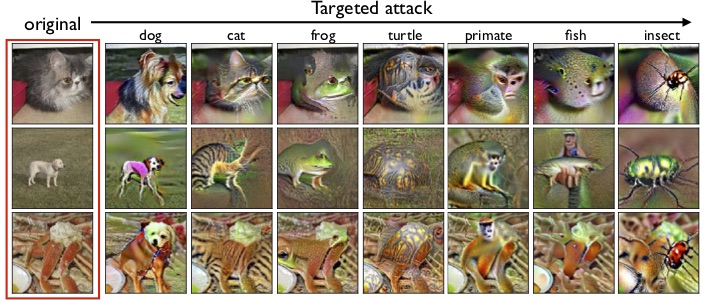
These results are also in line with our previous work, where we observed that large adversarial perturbations for robust models often actually resemble natural examples of the corresponding incorrect class.
In the rest of this post, we will explore how to perform a variety of computer vision tasks using only class maximization. It turns out that robustness is all you need!
Generation
We begin by leveraging robust models to generate diverse, realistic images. As we saw in the previous section, it is possible to introduce salient features of a target class into an input through class maximization. This simple operation alone turns out to also suffice to (class-conditionally) generate images.
To generate an image, we randomly sample a starting point (seed) and then execute (starting from that seed) the projected gradient ascent operation underlying class maximization. The key question here is: how do we sample the seed input? A natural idea is to just fit a Gaussian distribution to each class (in image space), and sample seeds from that distribution. Despite its simplicity, this approach already leads to fairly diverse and realistic samples:
We expect that there is still room for improvement; for example, one could replace Gaussians with a sophisticated class of distributions for seed sampling.
Image-to-Image translation
The ability to introduce perceptually meaningful, class-relevant features in image space (via class maximization) enables a very intuitive approach to performing image-to-image translation, the task of transforming inputs from a source to a target domain (e.g., transforming horses into zebras in photos). To perform this task, we first train a classifier to robustly distinguish between the two domains. This process encourages the classifier to learn key characteristics of each domain. We then perform image translation on an image from a given domain simply by using class maximization towards the target domain—this suffices! Here are some instances of our approach applied to typical datasets:
This is what a few particularly nice samples produced by our method look like:

Just as with image generation, we find reasonable solutions to the task using only class maximization on a robust classifier.
Inpainting
Next, we consider the task of image inpainting—recovering images with large missing or corrupted regions. At a high level, we would like to fill in the damaged regions with features that are human-meaningful and consistent with the rest of the image. Within our framework, the most natural way to do this is to perform class maximization (towards the original class) while also penalizing large changes to the uncorrupted regions of the image. The intuition being that this process restores the “missing” features while only minimally modifying the rest of the image. This is how a few random inpainted images produced by our method look like:
Interestingly, even when our method produces reconstructions that differ from the original, they are often still perceptually plausible to a human. Here are a few select samples:

Superresolution
To perform inpainting, we used class maximization to restore relevant features in corrupted images. The exact same intuition applies to the task of superresolution, i.e., improving the resolution of an image in a human-meaningful way. Specifically, using class maximization towards the underlying true class, we can accentuate image features that are distorted in the low-resolution image. Here we apply this method to images from the CIFAR10 dataset (32x32 pixels) to a resolution of 224x224 (7-fold upsampling):
Since the starting point of the underlying class maximization comes from a crude upsampling (i.e., nearest neighbor interpolation) of the low-resolution image, the final images exhibit some pixelation artifacts. We expect, however, that combining this approach with a more sophisticated initialization will yield even more realistic samples.
Interactive Image Manipulation
Finally, using this simple primitive, one can build an interactive toolkit for performing input space manipulations.
Sketch-to-image
Class maximization with robust classifiers turns out to yield human-meaningful transformations even for arbitrary inputs. This enables us to use this primitive to even transform hand-drawn sketches into realistic images. Here is the result of maximizing a chosen class probability from a very crude sketch:
You can draw realistic looking images with this method interactively here, without any artistic skill!
Paint-with-Features
In fact, we can achieve an even more fine-grained level of manipulation if we directly perform maximization on the representations learned by the robust model, instead of the class probabilities. (Recall that in the last post we saw how individual components can correspond to human-level features such as “stripes”.) By adding a human in the loop, we can choose particular regions of the image to modify and specific features to add. This leads to a versatile paint tool (inspired by GANpaint) that can perform manipulation such as this:
Here, we added a feature to a given region of the image by simply maximize the corresponding activation (a single component of the robust representation vector) while penalizing changes to the rest of the image. By successively performing such activation maximization in different parts of the image, we can paint with high-level concepts (e.g., grass or stripes).
Takeaways
In this blog post, we applied simple, first-order manipulations of the representation learned by a single robust classifier to perform a number of computer vision tasks. This is contrast to prior approaches that often required specialized and sophisticated techniques. Crucially, to highlight the potential of the core methodology itself, we used the same simple toolkit for all tasks and datasets, and with minimal tuning and no task-specific optimizations. We expect that the addition of domain knowledge and leveraging more perceptually-aligned notions of robustness will further boost the performance of this toolkit. Importantly, the models we use here are truly off-the-shelf and are trained in a standard (and stable) manner (via robust optimization).
Furthermore, our results highlight the utility of the basic classification toolkit outside of classification tasks. We hope that our framework will expand to offer ways to perform other vision tasks, on par with the existing state-of-the-art techniques (e.g., based on generative models). Finally, our findings highlight the merits of adversarial robustness as a goal that goes beyond the security and reliability contexts this goal was considered in so far.