In our previous post, we gave an overview of smoothing-based approaches to certified defenses, and described a certified patch defense known as de-randomized smoothing. In our latest work, we show how to leverage vision transformers (ViTs) to significantly improve such certified patch defenses along all possible axes: standard accuracy, certified accuracy, and speed. In fact, with some straightforward modifications, our certified ViTs not only enable significantly better certified robustness but they also maintain standard accuracy and inference times that are comparable to that of regular (non-robust) models. This progress marks a substantial step forward for certified defenses as a practical alternative to regular models.
The main appeal of certified defense is their ironclad guarantees: a certified result leaves no room for doubt and is not prone to blind-spots of empirical evaluation. However, practitioners care not only about certified performance: the accuracy and the inference speed of the model are equally important factors too. Unfortunately, nearly all certified defenses come at a severe price: (1) the standard accuracy plummets in comparison to a standard model and/or (2) inference time is orders of magnitude slower than that of a standard model.
This trade-off between robustness and performance can be untenable even for safety-critical applications. For example, object detection systems deployed in autonomous vehicles need to recognize obstacles and signs quickly in real time. Consequently, in addition to being robust, these systems also need to be fast and accurate.
To approach this tradeoff between robustness and accuracy, we take a closer look at certified defenses from an architectural perspective. Specifically, smoothing defenses use a backbone architecture that is typically implemented using classic convolutional networks, the default choice across much of computer vision. But are these architectures really the best tool for the job?
In our work, we show that when moving from standard models to certified defenses, it may be worth it to rethink the core architecture behind them. Specifically, we find that smoothing-based patch defenses can drastically improve when using vision transformers (ViTs) instead of convolutional networks as their backbone. With some additional adjustments to the transformer architecture, we not only achieve superior certified accuracy to prior work but also reach standard accuracies and inference times comparable to a standard, non-robust ResNet!
Rethinking smoothing backbones
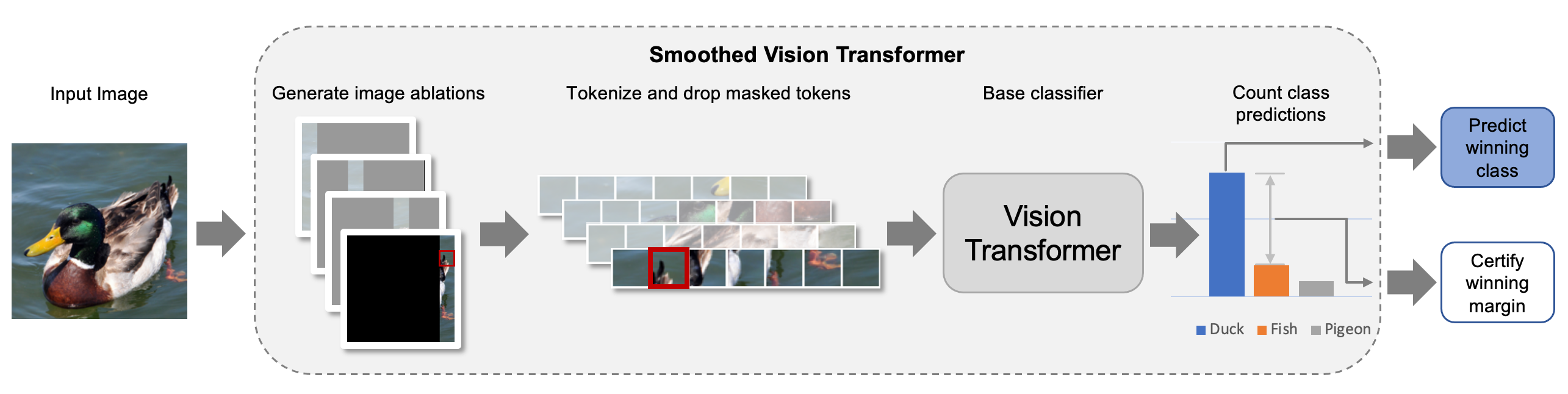
Recall from the previous post that smoothing defenses use a base classifier to make predictions on many variations of the original input. For patch defenses, this amounts to using the base classifier to classify column ablations (i.e., masked images that only reveal a small column of the original image). Consequently, the accuracy of the base classifier at classifying columns of an image directly translates into the performance of the certified defense.
In the light of this observation, it is crucial to realize that convolutional networks typically process
Why might we expect convolutions to be suboptimal for masked images? CNNs slide filters across the image and grow the receptive field across layers of the network. This large receptive field, while usually being a strength of CNNs for standard settings, forces the network to process a large amount of masked pixels when processing ablated images. Since these pixels carry no information, the network must learn to detect and ignore these masked regions (in addition to performing unnecessary computation).
Vision transformers for ablated images
Unlike CNNs, vision transformers (ViTs) use attention modules instead of convolutions as their main building block. Crucially, attention modules can ignore masked regions instead of processing them.
To test out this intuition, we measured the accuracy of various convolutional and ViT architectures at classifying column ablations. It turns out that ViTs are significantly better at this task—for example, on ImageNet, a ViT-S has 12% higher accuracy at classifying column ablations than a similarly sized ResNet-50.
These improvements in ablation accuracy directly boosts both the certified and standard accuracies for the smoothed model. For example, the increase in ablation accuracy improves the certified accuracy of a smoothed ViT-S by 13% (as compared to a similarly sized ResNet-50) and the standard accuracy by 12%.
With some additional adjustments to the certification procedure described in our paper, our largest certifiably robust vision transformer can reach 73% standard accuracy—only 3% off from the standard accuracy of a regular, non-robust ResNet-50, and almost 30% higher than previous versions of de-randomized smoothing!
Modifying ViTs to Speed up Inference Time
Also, recall that a smoothed classifier tends to be significantly slower than a standard model because it needs to classify a large number of input variations for each input image. Indeed, traditional randomized smoothing approaches have used upwards of 100,000 variations, resulting in a forward pass that is 4-5 orders of magnitude slower than a standard model. These costs are infeasible in scenarios where decisions need to be made in a fraction of a second, such as autonomous driving. As Levine & Feizi have shown, for patch defenses, a move towards deterministic smoothing (as opposed to randomized) can result in a great speed up (by reducing the number of variations needed to be classified). However, the resulting solution is still two orders of magnitude slower than standard models.
In order to speed up inference (much) further, we leverage the token-based nature of ViTs to gracefully handle image ablations. Specifically, note that ViTs process images as tokens, where each token represents a contiguous patch of the input image. Since the runtime of a ViT is proportional to the number of tokens, a natural approach to speed up inference is to simply drop the masked out tokens, as shown in the following figure:
We modify the ViT architecture to drop fully masked tokens in such a manner. As expected, this significantly speeds up the inference time of the smoothed model! Indeed, with this optimization, our smoothed ViT-S is faster than a smoothed ResNet-50 by an order of magnitude. In our paper, we discuss how additional improvements to the certification procedure can make our ViT architectures another order of magnitude faster. In total, our fastest smoothed ViT is actually comparable in terms of inference speed to a standard, non-robust ResNet.
Conclusion
Smoothed ViTs present a simple but effective way to achieve state-of-the art certified accuracy. These models are also realistically deployable, as they maintain similar accuracy and inference speed as non-robust models. The key here is the vision transformer’s inherent ability to quickly and accurately process image ablations. These advancements are thus a step towards certified defenses that can be practically deployed in real-world scenarios.