In our latest paper, we revisit the problem of data attribution and introduce TRAK—a scalable and effective method for attributing machine learning predictions to training data. TRAK achieves dramatically better speed-efficacy tradeoffs than prior methods, allowing us to apply it across a variety of settings, from image classifiers to language models.
As machine learning models become more capable (and simultaneously, more complex and opaque), the question of “why did my model make this prediction?” is becoming increasingly important. And the key to answering this question often lies within the data that the model was trained on.
Consequently, there’s been a lot of interest in (and work on) data attribution: how do you attribute a given prediction back to the individual data points in the training set?
Data attribution methods help us understand how the composition of the training data impacts model predictions. In particular, these methods have been shown to be useful for variety of downstream applications, such as identifying brittle model predictions, assigning data valuations, detecting mislabeled data, and comparing learning algorithms, among many others.
What is a data attribution method, exactly? One way to define a data attribution method is as a function that takes in a specific example $z$ and outputs a set of scores (one per training example) that denote the “importance” of each training example to a model’s prediction on $z$. In the context of image classification model, an example output of a data attribution method could look like this:

Prior works on data attribution, such as influence functions, Shapley values, empirical influences, and datamodels, all fit naturally into this definition.
Now, given all these data attribution methods and their various uses, what’s the need for yet another one?
Two desiderata for data attribution
There are two natural dimensions along which we’d want to evaluate data attribution methods: efficacy and speed.
- Efficacy: We want methods that provide data attributions that are reliable and faithful to the model’s decision process. (We’ll make this more precise soon.)
- Speed: At the same time, we’d like methods that are going to scale. Indeed, the ever-increasing scale of models and datasets makes only data attribution methods with a (very) modest dependence on model and dataset size practical.
Evaluating speed is pretty straightforward: we can just use
Evaluating efficacy, on the other hand, turns out to be somewhat tricky. Indeed, when we look at prior works, there is no unifying metric, and many works rely on qualitative heuristics such as visual inspection or proxies such as the recall rate for identifying mislabelled examples.
So how should one evaluate the efficacy of data attribution methods? Well, Inspired by our earlier work on this topic, we adopt the perspective that the overarching goal of data attribution is to make accurate counterfactual predictions: e.g., answers to questions of the form “what would happen to this prediction if a given set images were removed from the training set”?
To capture this intuition, in our paper, we propose measuring efficacy with a
new metric that we call linear datamodeling score (or LDS), which measures this
predictiveness as a
Efficacy vs. Speed tradeoffs
With the above metrics in hand, let’s take a look at existing data attribution methods:
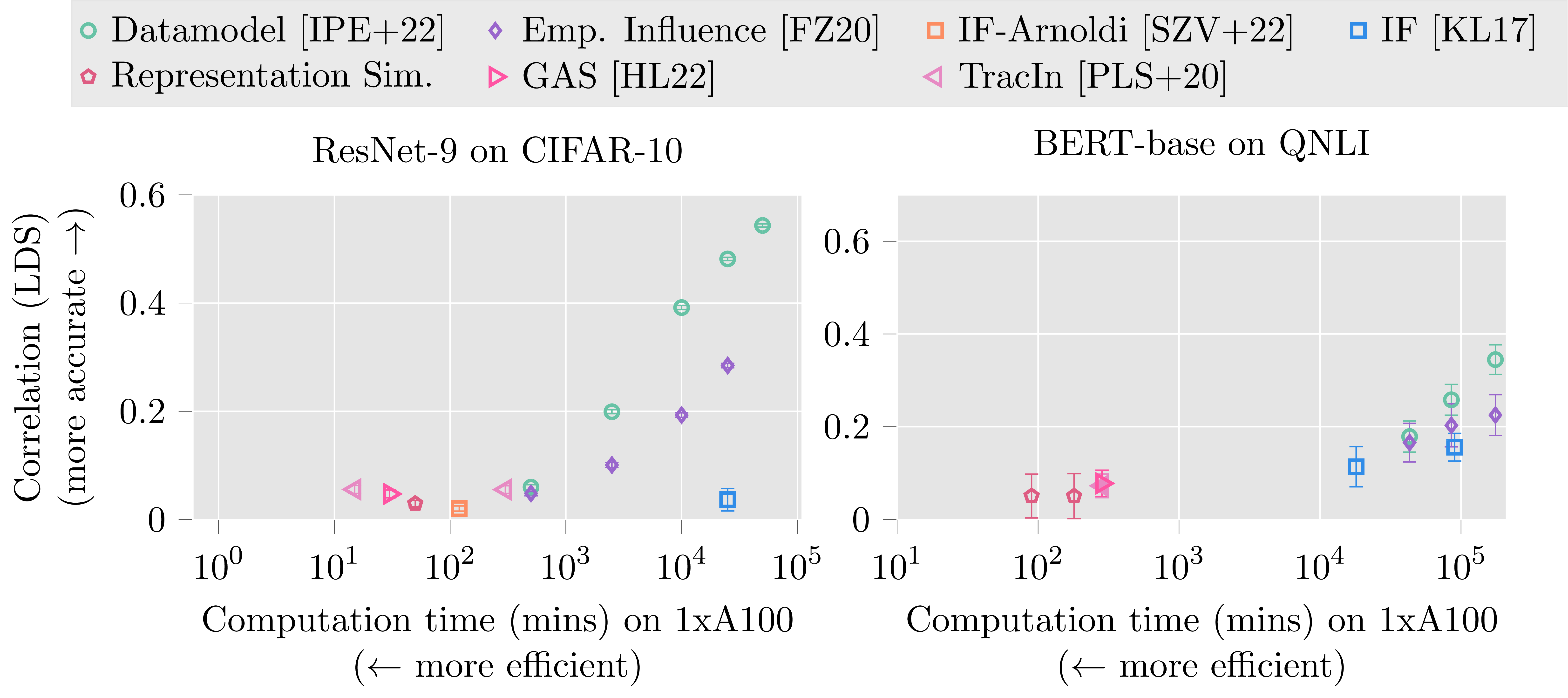
As we can see, attaining both efficacy and speed is a challenge for all data attribution methods that we evaluated—there’s nothing in the top left corner!
Indeed, on one hand, resampling-based methods (the green and purple points in the top right) are very effective, but also very costly. After all, these method requires re-training the model many times—and while this might be feasible when we’re studying ResNets on CIFAR-10 or ImageNet, it’s unclear what to do when studying models like CLIP or GPT-N on datasets like Open Images or Common Crawl.
On the other hand, there are methods like influence functions or TracIn that are fast but not very effective (they fall into the bottom left part of the above plot). Fundamentally, this is because the approximations made by these methods don’t quite capture the structure of complex models such as deep neural networks.
The above results raise the question:
Do we really have to pay such a heavy price for accurate data attribution?
TRAK: Effective, efficient data attribution
In our new paper, we introduce TRAK (Tracing with the Randomly-Projected After Kernel), a new data attribution that significantly improves upon existing tradeoffs between efficacy and speed in data attribution.
We’ll leave the math to the paper, but the principle behind TRAK is quite simple: we approximate the model of interest with an instance of kernel regression (using the so-called “after kernel”); we randomly project the corresponding features to a lower-dimensional space; and then we apply (known) heuristics for data attributions in the kernel regression regime to perform data attribution on the original model.
Here is our previous plot with TRAK added to it (note the x axis scale!):
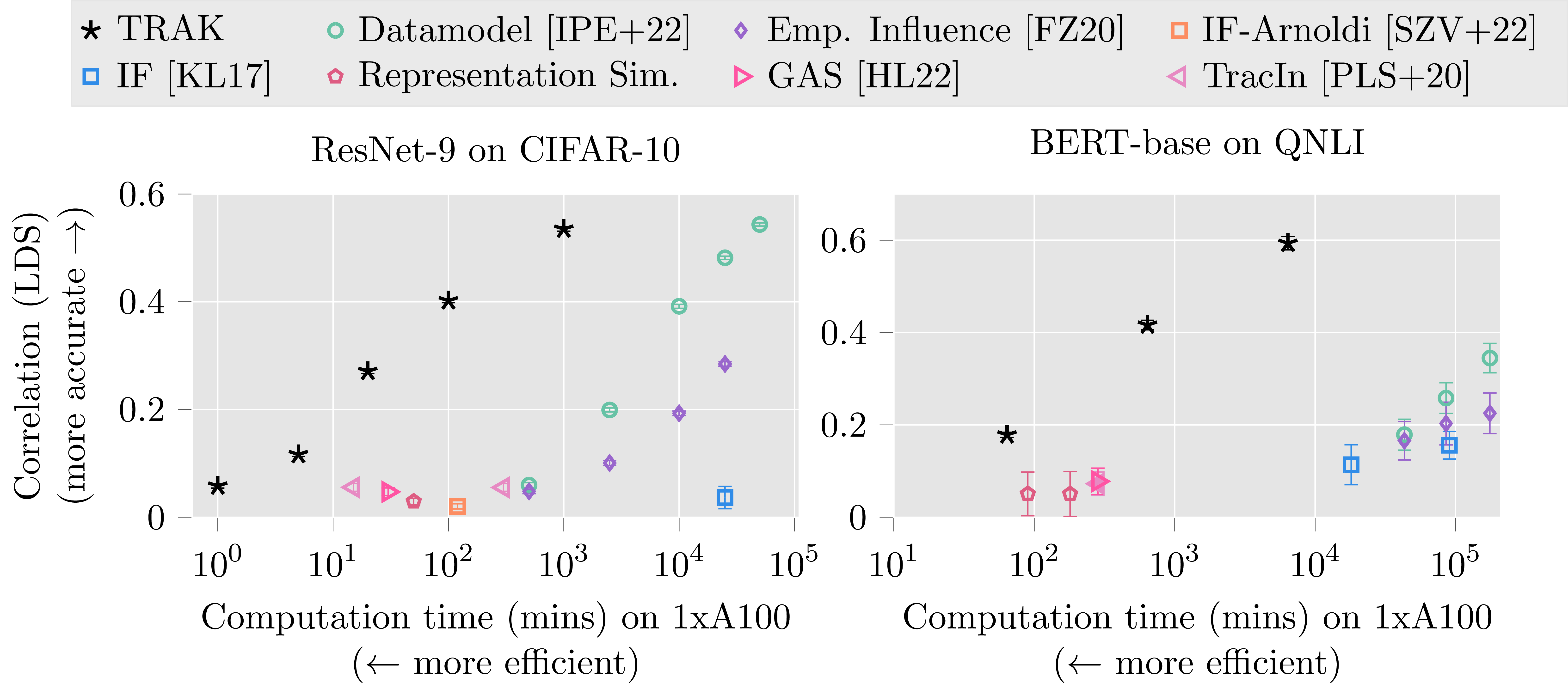
As we can see, TRAK fares pretty well here: it is 100x faster than models of comparable efficacy, and (at least) 10x more effective than models of comparable speed. As an example: for BERT models finetuned on the QNLI dataset, TRAK scores computed in just 17 hours on a single A100 GPU are more effective than re-training based datamodels computed in 125 GPU-days. TRAK is also significantly more effective than comparably fast methods, such as influence function-based methods or TracIn.
Applying TRAK across models and modalities
TRAK applies out-of-the-box to a wide variety of machine learning problems—including across modalities (e.g. language & vision among others), architectures (e.g. CNNs, Transformers, etc) and tasks (classification, contrastive learning, question answering, etc).
In our paper, we apply TRAK to ResNets trained on CIFAR and ImageNet, BERT-base models trained on QNLI, CLIP models trained on MS COCO, and mT5 models fine-tuned on a fact tracing benchmark. In each of these applications, we show that TRAK is significantly more effective at counterfactual prediction than existing baselines.
Next, we’ll take a closer look at two of such applications: CLIP, and (transformer-based) language models—two families of models that have become very popular and useful in the last few years.
Application #1: Attributing CLIP
CLIP (Contrastive Langauge-Image Pre-training) representations are a powerful tool for translating between vision and language domains. State-of-the-art CLIP models are trained on gigantic datasets of image-caption pairs, and properties of the training datasets seem to play a big role in the quality of the resulting representations.
But which training examples actually play the key roles in learning a given image-caption pair association? We can use TRAK to study this question. Below, for a few different image-caption pairs, we show the top training examples identified by TRAK:


You can see that nearest neighbors identified both by TRAK and by the CLIP representations themselves are semantically similar to the target images. But good attribution is more than just finding similar examples—they must actually be important to how the model makes decisions.
To evaluate this, we first, for each image-caption pair we remove the $k=400$ examples with the most positive TRAK scores; train a new CLIP model on the rest of the training set; and measure the model’s alignment (in terms of cosine similarity) on the image-caption pair being studied. The resulting models are on average 36% less aligned on the corresponding image-caption pairs. Even with removing just $k=50$ examples, you can see that the cosine similarity degrades quite a bit (a 16% drop).
Now, if we do the same but instead remove the most similar examples according to CLIP (or remove similar examples according to TracIn, an existing data attribution method), the resulting drop in cosine similarity is much less profound: compare 36% from TRAK to 11% for CLIP representations and 4% for TracIn scores, respectively.
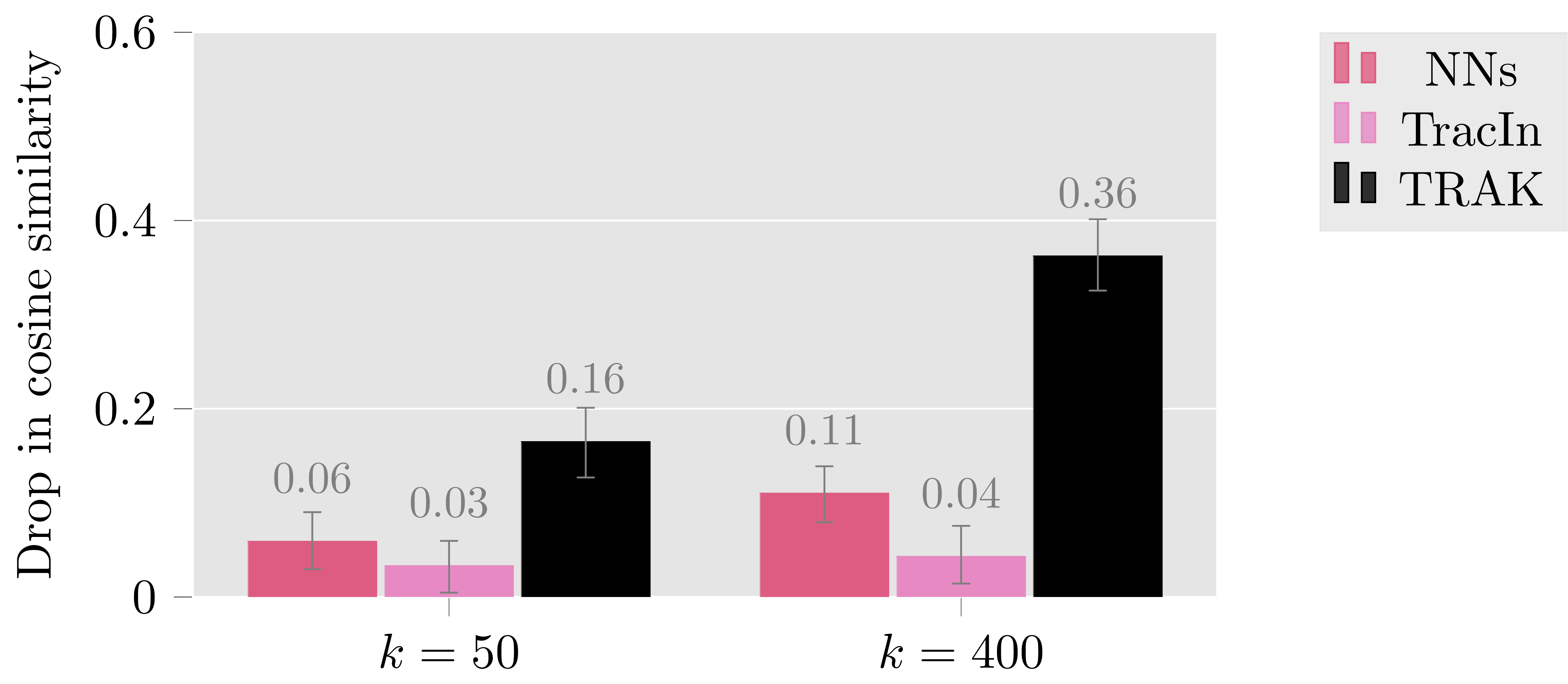
TRAK thus identifies training examples that are
Application #2: TRAK for Model-Faithful Fact Tracing
Next, we look at another application of TRAK that we found to be particularly interesting: the problem of fact tracing. That is, tracing factual assertions made by a language model back to corresponding data sources in the training set expressing those facts.
Specifically, we applied TRAK to a fact-tracing benchmark called FTRACE-TRex. Briefly, the goal of this benchmark is to identify the data sources responsible for a given fact expressed by a large language model.
The test set of FTRACE-TRex is a set of “queries”. Each query pertains to a particular fact, and is annotated with a set of “ground-truth proponent” training examples that express the same fact. So if “Paris is the capital of France” was a test set query, its ground-truth proponents in the training set might include, say,
- “The capital of France is Paris,”
- “The beautiful capital city of Paris, France, comes alive at night,”
- “Paris, France is one of the busiest capital cities in Europe”
The FTRACE-TRex benchmark captures a data attribution method’s ability to surface these ground-truth proponents as the “most important” training examples for their corresponding queries. (That is, a good data attribution method should assign high scores to a query’s ground-truth proponents, relative to the rest of the training set.)
To our surprise, TRAK, while outperforming the previous best data attribution method (TracIn) on this task, did worse on this benchmark than a simple information-retrieval baseline (BM25)—this baseline is based only on the lexical overlap between the query and the possible data sources, and doesn’t even look at the model at all!
To understand the possible roots of TRAK’s underperformance here, we carried out a counterfactual analysis. What we found was that when we removed the training examples that TRAK identified as the most important (despite these being the “wrong” ones according to the FTRACE-TRex benchmark), the model was indeed less likely to express the corresponding facts. More crucially, though, this effect was actually stronger when we removed TRAK-identified examples than when we removed BM25-identified examples, and even stronger than when we removed the ground-truth primary sources!
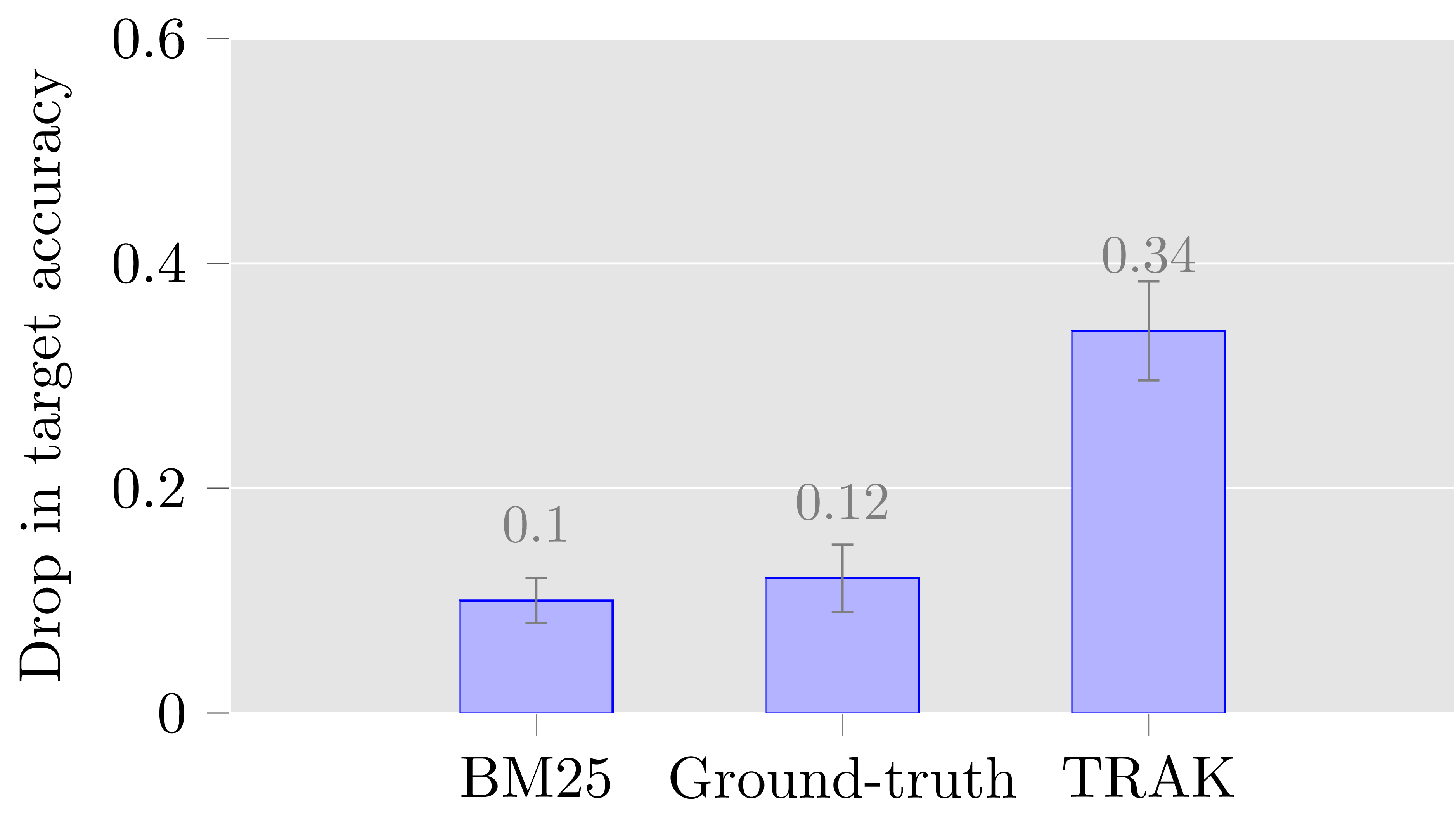
We’ll leave the details of our experiment to the paper, but our result highlights a difference between “fact tracing” and data attribution (which might be more appropriately called “behavior tracing”). That is, finding a data source that factually supports a language model’s output is a different task than identifying the actual data sources that caused the model to generate that output. One might try to solve the former task with techniques such as information retrieval or web search (to “cite” sources). But the latter task is fundamentally one that cannot be decoupled from the model—and TRAK seems to be a promising approach here.
More broadly, we think that TRAK can be a useful tool in getting a more data-driven understanding of learning mechanisms underlying LLMs.
Attributing with TRAK: The PyTorch API
With the evaluation and examples above, hopefully we made a case that TRAK can be an effective and efficient data attribution method. But what does it take to apply it to your task?
We made sure that using TRAK is as easy as possible. To this end, we’re
releasing trak as a
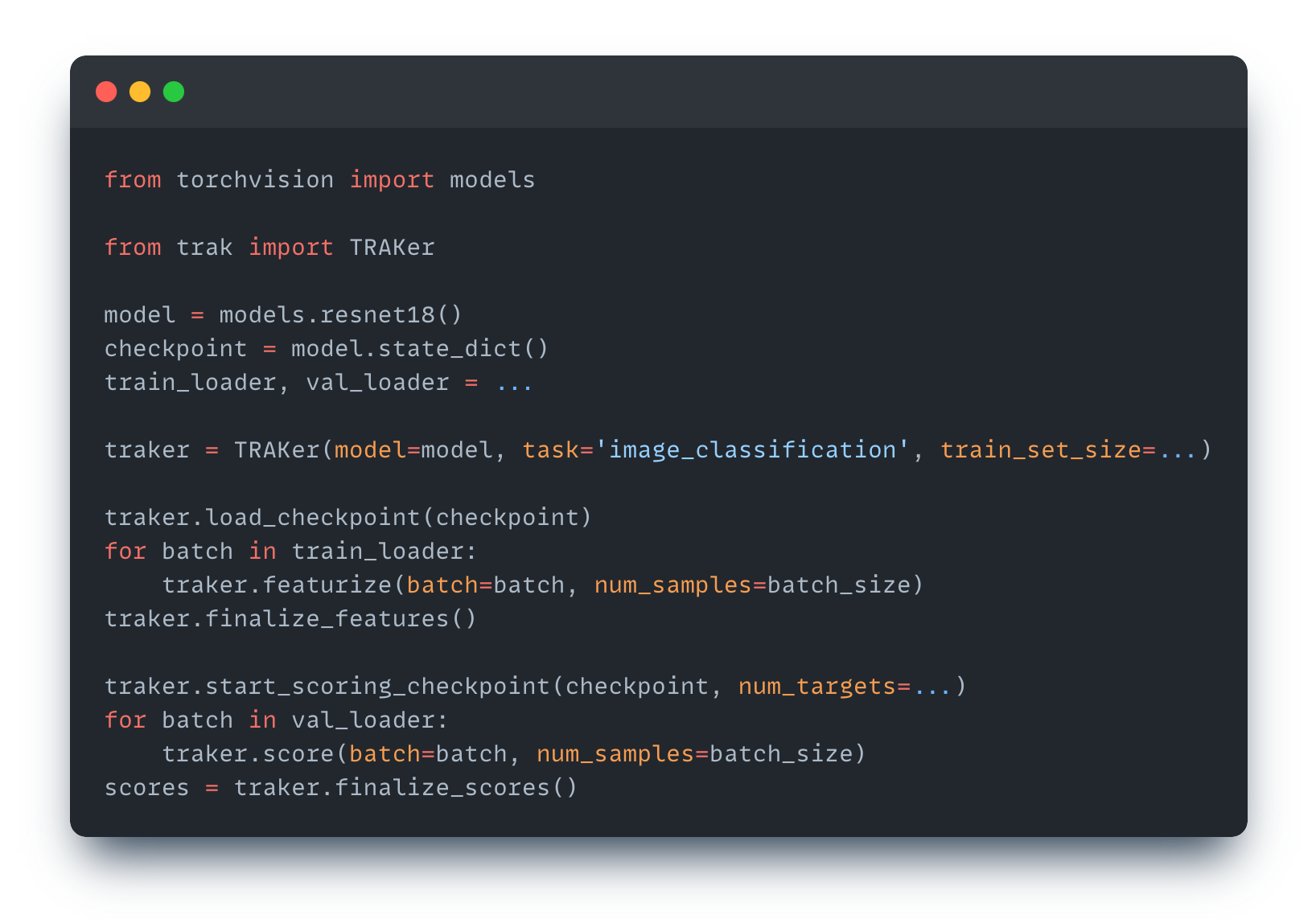
We provide built-in TRAK functions for popular applications such as analyzing image classifiers, CLIP models, and text classifiers. The API also makes it easy to adapt TRAK for new, custom tasks.
You can get started with installation here. See our code and documentation, as well as tutorials and examples for more details.
Conclusion
In this post, we considered the problem of data attribution—i.e., tracing the behavior of machine learning models back to their training data. Our new method, TRAK, can provide attributions that are accurate and orders of magnitude more efficient than comparably effective methods.
Prior works have already shown the wide utility and potential of data attribution methods, including explaining predictions, debugging model behavior, assigning data valuations, and filtering or optimizing data. But, the main bottleneck in deploying these methods was their lack of scalability or predictiveness in modern settings. We believe that TRAK significantly reduces that bottleneck and that using TRAK in these downstream applications will accelerate and unlock many new capabilities, particularly in settings where training is very expensive, such as large language models.
We are excited about the possibilities enabled by TRAK. See the paper for more details, or get started right away applying TRAK to your problem with our library!