Language models may need external information to provide a response to a given query. A user would provide this information to a language model as context and then expect the model to interact with this context when responding to the query.
For example, suppose that I want to use an AI assistant like ChatGPT to help me plan a trip to see a solar eclipse this week. I would first need to provide it with relevant documents about the path of the eclipse and weather forecasts. Then, I could ask it to use this information to compile an itinerary.
Upon seeing the generated response, I might ask: is everything accurate? Did the model misinterpret anything or make something up? Is the response actually grounded in the provided context?
We introduce ContextCite, a method that can help answer these questions. Here’s an example of what it can do (check out our demo and Python package to play around with it yourself):
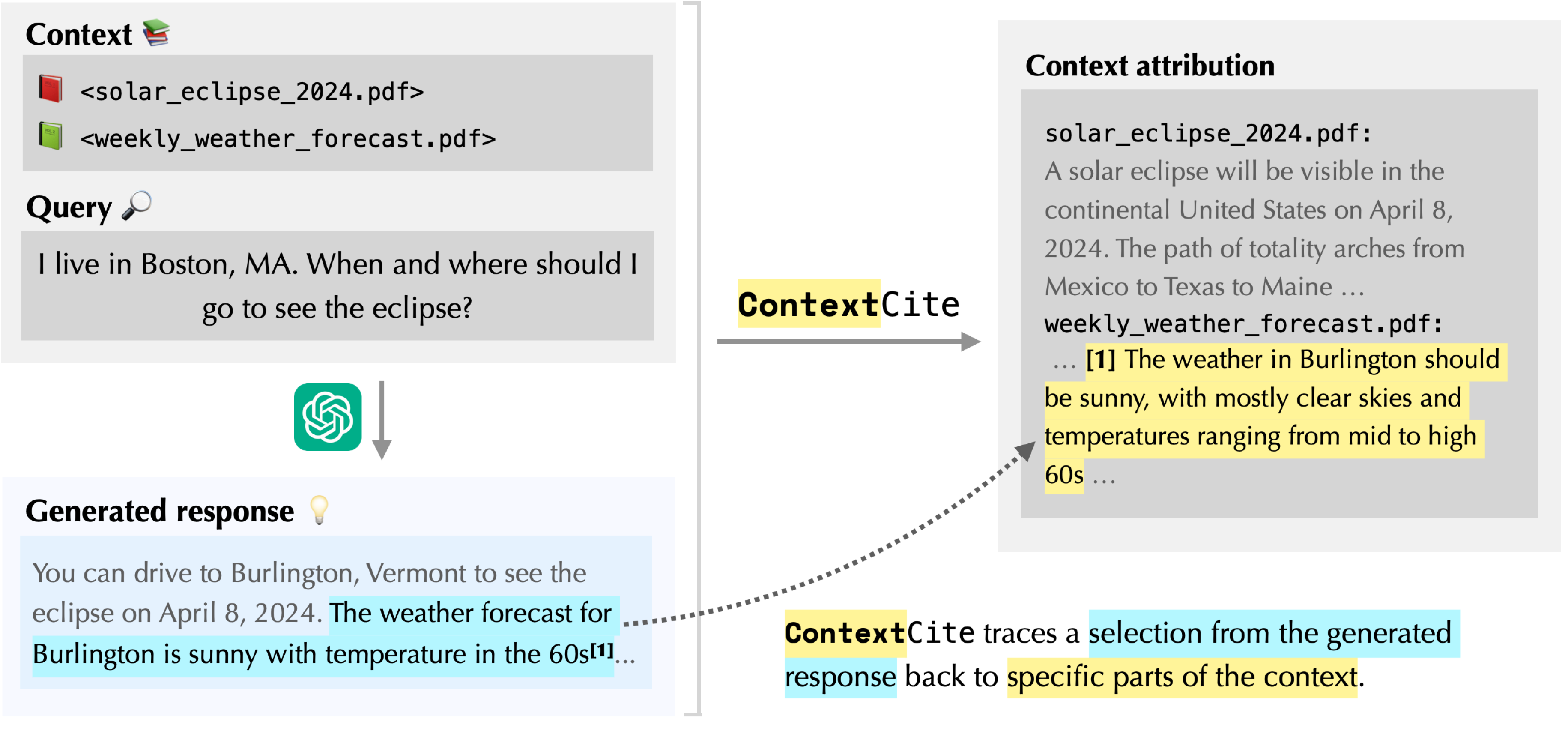
As we see in the figure above, ContextCite finds that the sentence “The weather in Burlington should be sunny, with mostly clear skies …” is responsible for the model stating that “The weather forecast for Burlington is sunny …”. This checks out!
But as we know, models can sometimes act in unpredictable ways. Consider the following example:






Here, the language model generates a long answer containing multiple statements. Using ContextCite, we can pinpoint the parts of the provided context (if any) that are responsible for a given statement. Try it out yourself by hovering over the highlighted output sentences.
So, how does ContextCite work? In the rest of this blog post, we will explain this in detail. To this end, we first define the task of context attribution: pinpointing the parts of the context that are responsible for a given generated statement. Then, we describe ContextCite, a simple and scalable method for context attribution, and benchmark its effectiveness against a few natural baselines. In a follow up blog post, we explore using ContextCite to detect misinterpretations, unverified statements and poisons within the context. We are excited about how context attribution can help make LLMs into more reliable tools!
What is Context Attribution?
Intuitively, the goal of context attribution is to trace a part of the generated response back to a piece of the context. Specifically, suppose that we are given a context 📚and query $Q$. For example, the context might be a bunch of articles about the most recent Olympics and the query might be “Who won the most medals?” To perform context attribution, we first partition the context 📚 into individual sources 📗$_1,$📕$_2,\dots,$📘$_n$. We can partition at any desired granularity: for example, the sources can be the articles, paragraphs or sentences within the articles, or even individual words. In the rest of this blog post, we will consider sources to be sentences.
Now that we have our sources, we are ready to perform attribution. A context attribution method $\tau$ accepts a part of the generated response (a subset of the tokens corresponding to a statement of interest) and assigns a score to each source. This score is intended to signify the “importance” of the source to generating this statement:

In practice, we might want an attribution set, i.e., a set of the most relevant sources. To obtain such a set, we can apply a threshold to our scores as a post-processing step.
What do context attributions scores signify?
So far, we’ve only said that scores should signify how “important” a source is for generating a particular statement. But what does this actually mean? There are two types of attribution that users might care about.
Corroborative attribution identifies sources that support or imply a statement. Meanwhile, contributive attribution identifies the sources that cause a model to generate a statement. If a statement is accurate, then its corroborative and contributive sources may very well be the same. However, if a statement is inaccurate, corroborative and contributive attribution methods would likely behave differently. Indeed, suppose, for example, that a model misinterprets a fact in the context. A corroborative method might not find any attributions (because nothing in the context supports its statement). On the other hand, a contributive method would identify the fact that the model misinterpreted.
There are several existing methods for corroborative attribution of language models. These typically involve explicitly training or prompting models to produce citations along with each statement they make. Many AI-powered search products provide these types of citations (they remain hard to verify).
ContextCite, however, provides contributive attributions. As we will see, this type of attribution gives rise to a diverse and distinct set of use cases and applications compared to existing corroborative methods (e.g., detecting misinterpretations, finding poisoned contexts).
Evaluating the quality of attributions
How can we assess the quality of a contributive attribution method? Intuitively, if a source is important, then removing this source should change the response significantly. Following this intuition, one way to evaluate a context attribution method is to see what happens when we remove the $k$ highest-scoring sources. Specifically, we measure how much the log-probability assigned by the model to the original response drops:
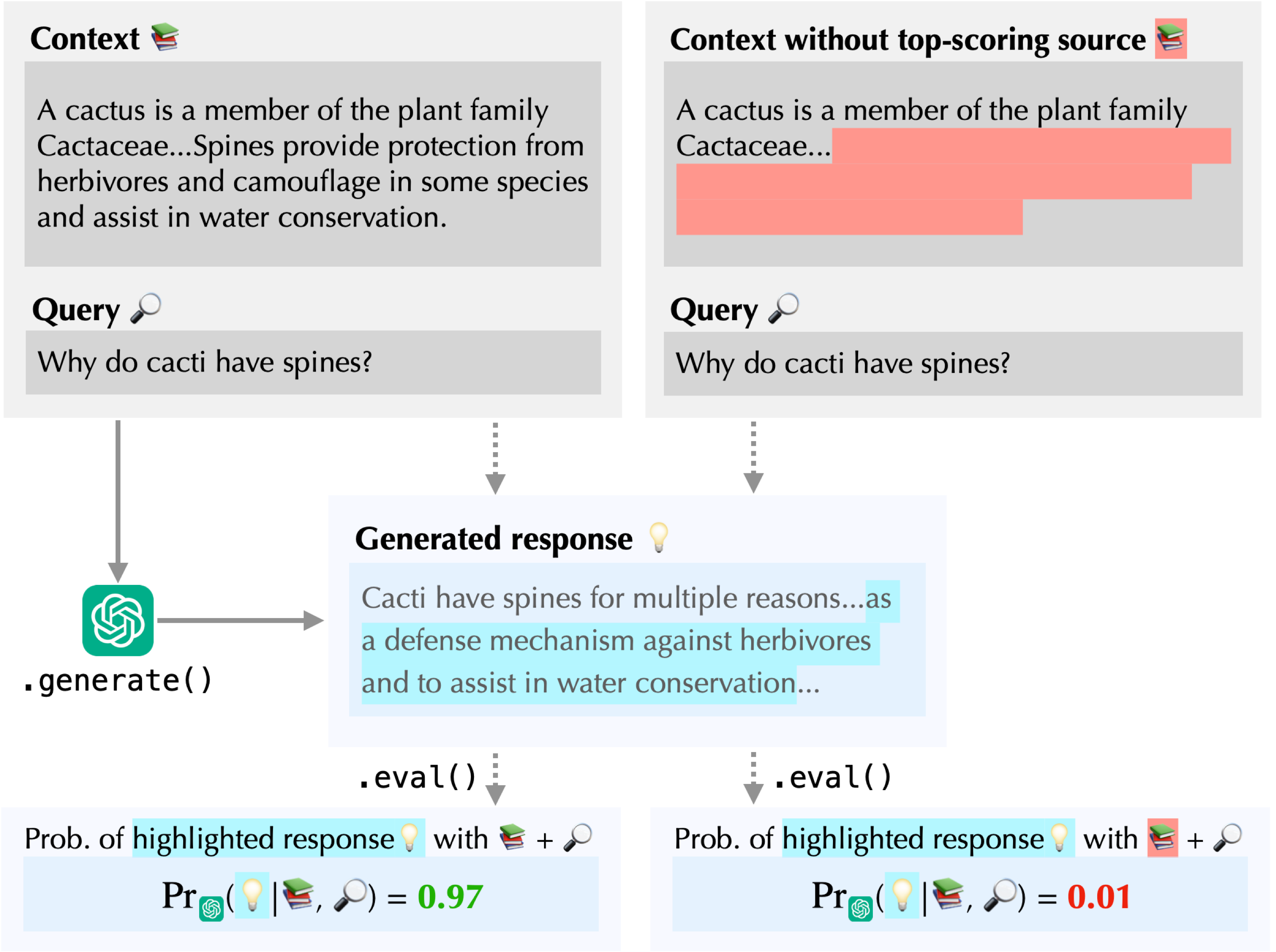
In this example, the highest-scoring source is the key piece of the context from which the model concludes that cacti have spines “as a defense mechanism against herbivores and to assist in water conservation.” When we remove it, the probability of this response decreases substantially, indicating that this source is indeed important. More generally, if removing the highest-scoring sources of one attribution method causes a larger drop than removing those of another, then we consider the former method to be more accurate.
ContextCite
We have established that a context attribution method is effective insofar as it identifies sources that would significantly alter the response if they weren’t present. Can we model this process directly? That is, is there a simple model that predicts how the probability of the original response would change when we exclude a subset of the sources?
Aside: we’ve explored a similar line of thinking—understanding via surrogate modeling—in our work on datamodeling and component modeling. For example, in datamodeling, a linear surrogate model encodes how every example in the training dataset contributes to the model prediction on a given test example. As we will see, the types of surrogate models that are effective for datamodeling, namely, sparse linear models with logit-scaled probabilities as targets, also work quite well in the context attribution setting.
It turns out that the answer is yes! And this is exactly what drives the design of ContextCite. Specifically, ContextCite comprises the following steps:
- Generate a response for the given context and query (nothing new here).
- Randomly ablate the sources in the context (i.e., pick a fraction of the
sources to exclude and construct a modified context without them).
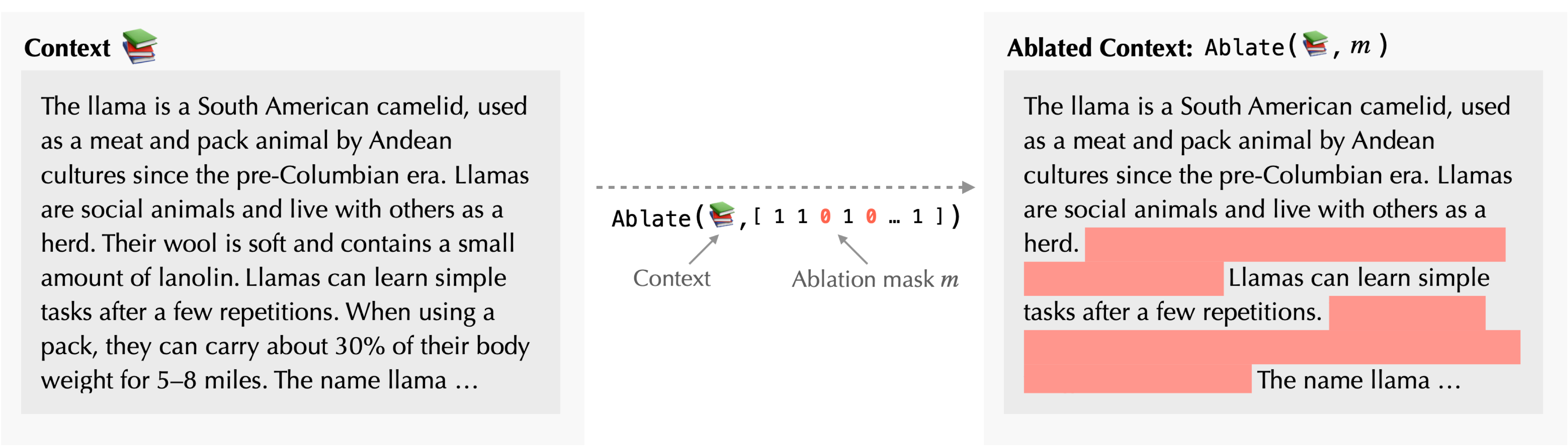 Then, compute the probability of generating the original response. Repeat this
several times to create a “training dataset” of ablation masks and the resulting
probabilities.
Then, compute the probability of generating the original response. Repeat this
several times to create a “training dataset” of ablation masks and the resulting
probabilities. - Fit a surrogate model to estimate the probability of generating the original response as a function of the ablation mask.
The figure below summarizes ContextCite:

In practice, we find that (just as in datamodeling) a linear surrogate model predicting logit-scaled probabilities is quite effective!
We can then treat this surrogate model’s weights as attribution scores denoting the importance of each source to the generated content.
Sparsity to the Rescue!
A natural question to now ask is: how many random context ablations do we need to compute to get an accurate surrogate model? Since we’re solving a linear regression problem, we would expect the number of ablations to scale linearly with the number of sources. But given that each ablation that the surrogate model learns from requires an additional inference pass of the model that we’re attributing, we would want to keep the number of ablations lower than that.
It turns out that ContextCite is able to learn an accurate surrogate model with a significantly smaller number of ablations by exploiting underlying sparsity. In particular, in many cases a statement generated by the model can be explained well by just a handful of sources. This means that most sources should have very little influence on a particular statement. Hence, we can use Lasso to learn a sparse (yet still accurate) linear surrogate model using a very small number of ablations.
Indeed, in our demo and evaluations, we can use only 32 ablations even when the context consists of hundreds of sources!
The following figure shows the weights of the surrogate model used by ContextCite to attribute a Mistral-7B-Instruct model’s response to the question “Can you over-water a cactus?” using the Wikipedia article about cacti as context.
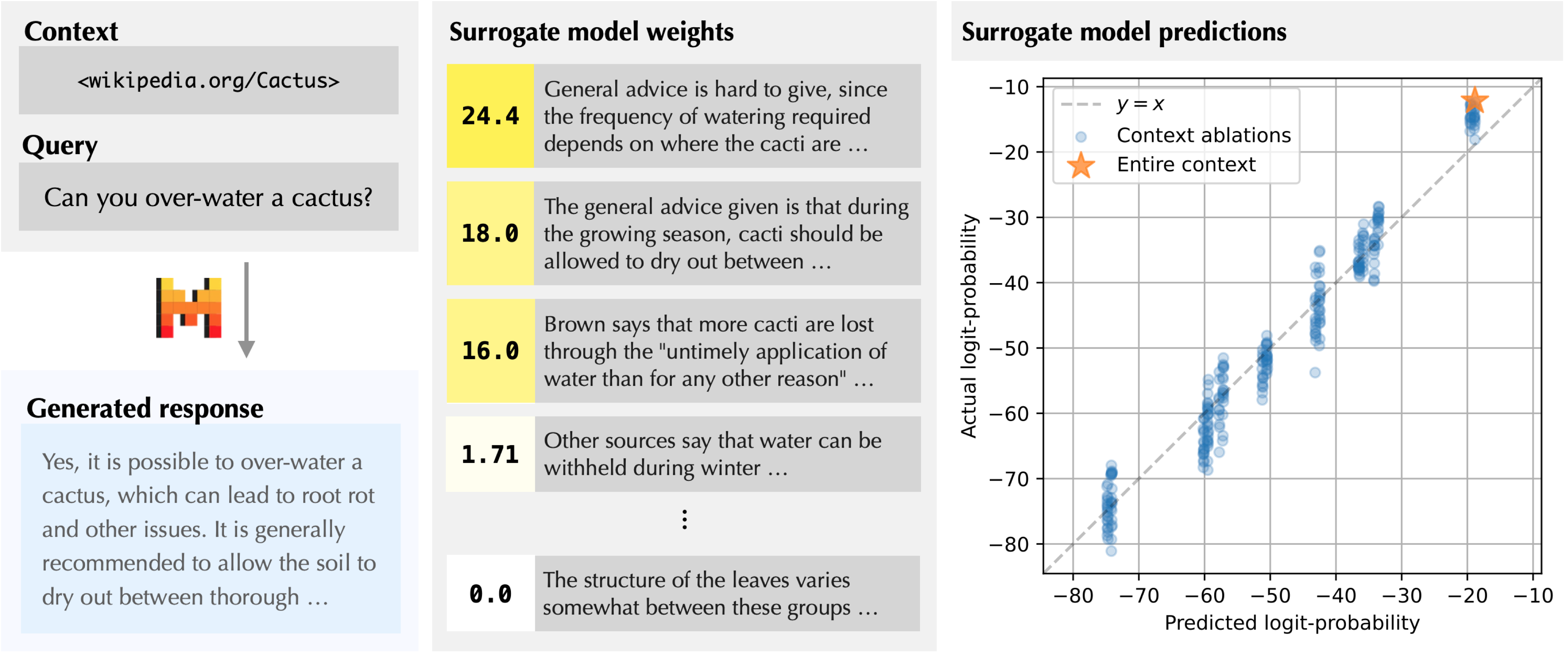
In the middle, we can see that there are three sentences in the entire Wikipedia article with weights much higher than the rest–these three sentences are primarily responsible for the response. On the right, we show the surrogate model’s predictions of the logit-probabilities and the actual logit-probabilities for a bunch of random context ablations and for the entire context. The surrogate model appears to be quite accurate! The “vertical clusters” are caused by the sparsity induced by the $\ell_1$-regularization used in Lasso: most of the model’s prediction is determined by the presence or absence of each of the three key sentences.
Connections to prior work
Besides datamodeling and component modeling, several works have explored using surrogate models to explain and attribute model behavior. We have thought about this a lot in the past. Other recent work has applied datamodels to the in-context learning setting to select better examples to show as demonstrations. In the interpretability literature, LIME uses local sparse linear surrogate models to explain a model’s prediction in terms of features.
How effective are ContextCite attributions?
ContextCite is designed to identify the sources in the context that explain why a model generated a particular piece of content. How effective is it at doing so? We benchmark ContextCite against three natural baselines for context attribution adapted from prior work:
- Attention: following works discussing attention as an explanation for language model behavior, we average the last-layer attention score of the selected response to attribute to each of the sources.
- Similarity: we embed the selection to attribute and each of the sources using an off-the-shelf pre-trained model, and treat the embedding cosine similarities as attribution scores.
- Gradient: we compute the gradient of the selection to attribute with respect to each source, and treat the norms of the gradients as attribution scores.
As we discussed before, we quantify the effectiveness of an attribution method by ablating the $k$ highest-scoring sources and measuring the drop in the log-probability of the original response (normalized by the length of the response). Across different tasks, ContextCite consistently outperforms baselines:
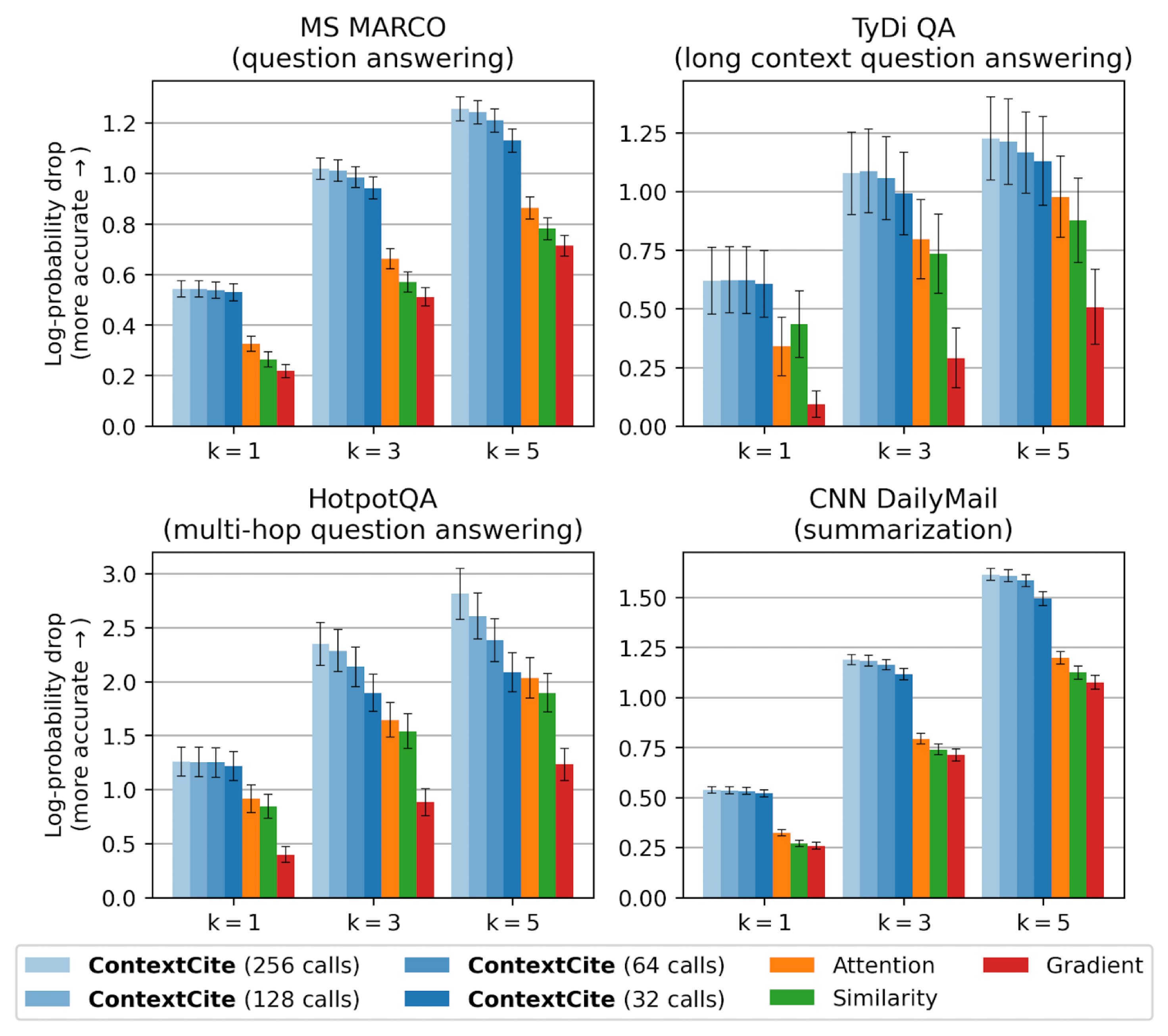
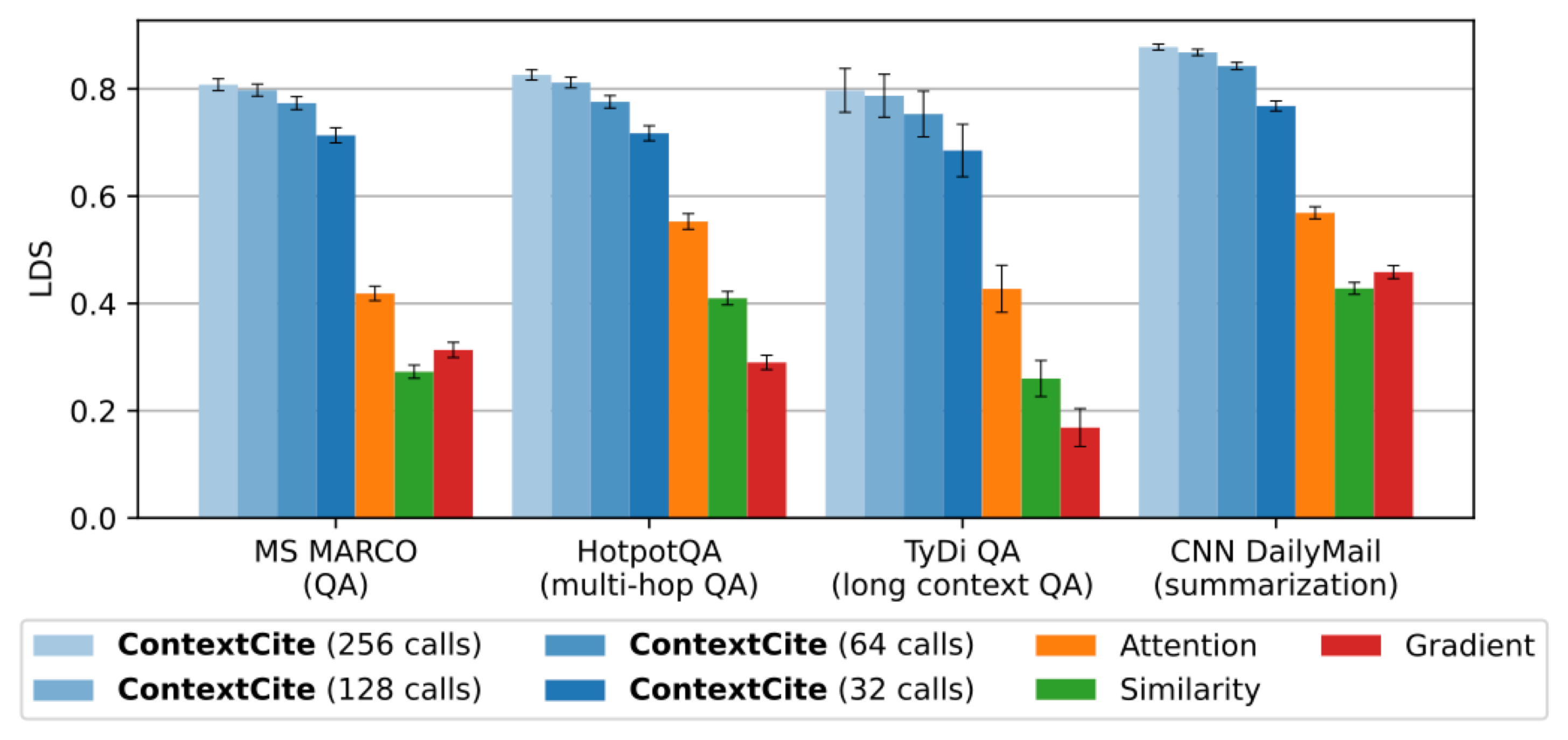
For a more fine-grained evaluation, we also consider whether attribution scores can accurately rank the effects of ablating different sets of sources. In the data attribution literature, the linear datamodeling score (LDS) measures exactly this (there, it ranks the effects of ablating different sets of training examples). In terms of LDS too, we find that ContextCite outperforms baselines:
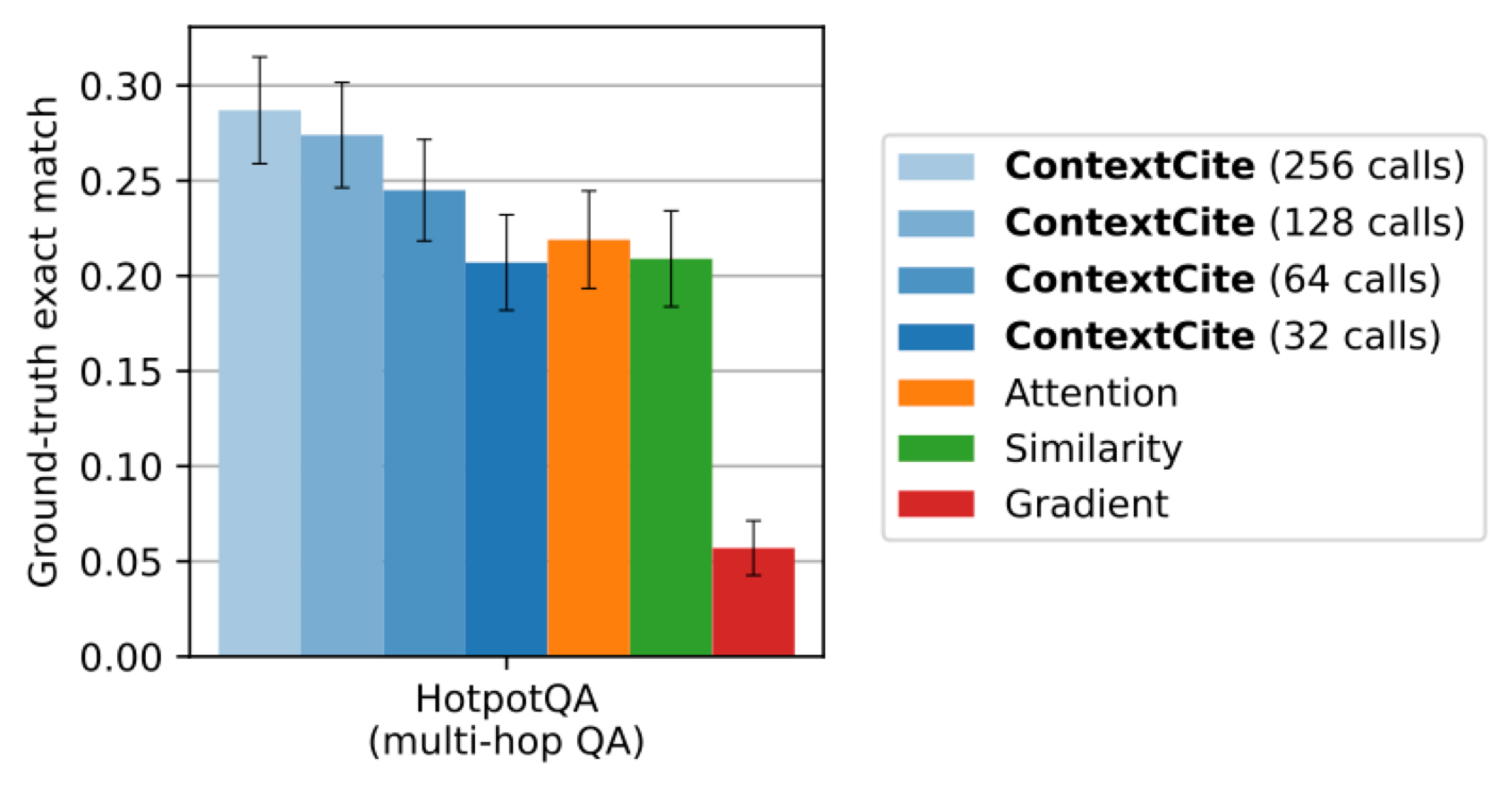
So far, we’ve seen that ContextCite learns accurate contributive attributions. Indeed this is what ContextCite is designed to do. However, we might also be interested to see if ContextCite identifies the ground-truth sources for a query when they are available. The Hotpot QA dataset above includes an annotation of the precise list of sentences needed to answer each question. We find that ContextCite is also effective at identifying these ground-truth sources, compared to baselines:
Conclusion
In this post, we introduce the problem of context attribution: pinpointing the parts of the context that are responsible for specific statements generated by a language model. We present ContextCite, a scalable method for context attribution that can be flexibly applied to any existing language model.
In the next post, we dive deeper into how we can use ContextCite to determine whether we should trust the content generated by language models. Stay tuned for more!